eBPF Talk: SKB 工作原理【译】

文章目录
翻译自 How SKBs work。
数据区域的布局
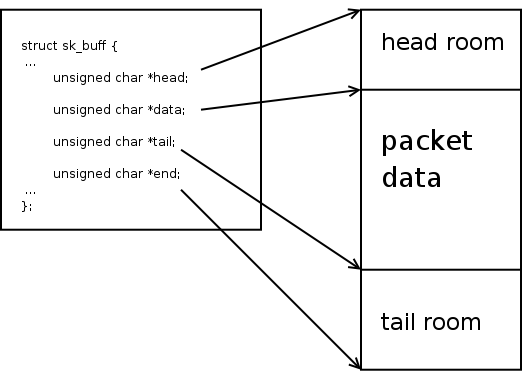
第一张图描述的是 SKB 数据区域的布局,以及几个 struct sk_buff 中的指针。
本文余下内容将讲解 SKB 数据区域的操作:通过修改这些指针,从而做到增加头部、用户数据、和取出头部。
同时,我们也会讲解非线性区域的实现,及其工作方式。
初始化状态
|
|
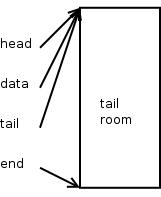
这是使用 alloc_skb() 分配内存后 SKB 的样子。
可以看到,head、data 和 tail 指针都指向数据区域的开头,end 指针指向其结尾。此时,所有数据区域都可以认为是尾空间。
此时,SKB 的长度是 0,因为它还没包含任何网络包数据。让我们使用 skb_reserve() 为协议头预留一些空间吧。
预留空间
|
|
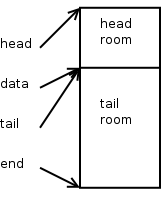
这是 skb_reserve() 后 SKB 的样子。
准确来说,当构建发送的网络包时,我们预留我们认为头部空间所需的最大数量的字节数。大部分时候,IPv4 协议能通过套接字值 sk->sk_prot->max_header 拿到该最大数量。
当构建以太网设备需要 DMA 的接收的网络包时,我们需要调用函数 skb_reserve(skb, NET_IP_ALIGH)。其中 NET_IP_ALIGN 默认定义为 2。这是为了协议头都对齐 4 字节。近乎所有的 IPv4 和 IPv6 协议都假定所有协议头都是对齐的。
现在,让我们给网络包加点用户数据吧。
添加用户数据
|
|
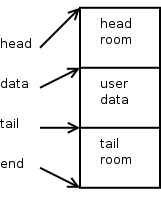
这是添加用户数据后 SKB 的样子。
skb_put() 给 skb->tail 添加了用户数据的字节数量,同时为 skb->len 增加了同样的字节数量。如果 SKB 里已有分页数据,就不能调用该函数。同时,需要保证 SKB 里有足够的尾空间去添加用户数据。在调用 skb_put() 前需要检查这两个条件,否则将触发断言失败。
计算的 checksum 保存在 skb->csum。现在,是时候去构建协议头了。我们将构建一个 UDP 头,然后是一个 IPv4 头。
添加 UDP 头
|
|
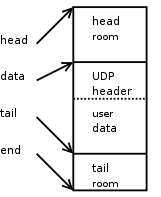
这是在 SKB 开头添加完 UDP 头后 SKB 的样子。
skb_push() 将 skb->data 指针减少给定字节数量;同时将 skb->len 增加同样的数量。调用者需要确保 SKB 里有足够的头空间去添加协议头。在调用 skb_push() 前需要检查该条件,否则将触发断言失败。
现在,是时候添加 IPv4 头了。
添加 IPv4 头
|
|
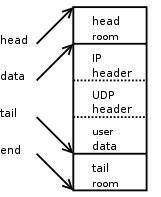
这是在 SKB 开头添加完 IPv4 头后 SKB 的样子。
跟添加 UDP 头的处理一样,skb_push() 减小 skb->data 并增大 skb->len。我们使用 skb->nh.raw 指针指向新空间的开头,然后构建 IPv4 头部。
该网络包已基本准备好发送出去了,只要我们能够(从邻居子系统和 ARP)拿到用于构建以太网头部的必要信息。
分页数据
一旦用到分页数据,事情就开始变得更加复杂了。有了 SKB 数据的 [page, offset, len] 元组后,文件系统的文件内容就能够直接通过套接字传输了。然而,有的时候,这有益于 sendmsg() 发送数据。
必须谨记的是,一旦 SKB 中开始使用分页数据,SKB 数据的所有操作都会受到限制。特别指出,此后不能再使用 skb_put() 操作了。
至此,我们会提及两个跟 SKB 长度有关的变量:len 和 data_len。后者只有当 SKB 里有分页数据时才有。skb->data_len 指的是 SKB 中有多少字节的分页数据。从中我们可以看出:
- SKB 中有分页数据的表征是
skb->data_len不为 0。skb_is_nonlinear()就是用来测试是否为 0 的那个函数。 skb->data中非分页数据的字节数可通过skb->len - skb->data_len计算得到。与此同时,skb_headlen()就是那个计算函数。
主要抽象逻辑如下:当有分页数据时,从 skb->data 开始是 skb_headlen(skb) 字节,然后是 skb->data_len 字节的分页数据区域。这就是当有分页数据时不能使用 skb_put(skb) 的原因。因而,你需要将数据添加到分页数据区域的末尾。
SKB 中每个分页数据块的结构体如下:
|
|
此结构体中有指向(你必须持有合适引用的)分页的指针,该分页中该数据块分页数据起始的偏移量,和分页字节数量。
这些分页碎片由共享的 SKB 区域组织成一个数据,其定义如下:
|
|
其中 nr_frags 属性表明 frags[] 中有多少个存活的分片。tso_size 和 tso_segs 表明设备驱动中 TCP 分片卸载(TSO)所需要的信息。frag_list 用来保存分片所需的 SKB 链表,而不是用来保存分页数据。最后 frags 保存了其自身的碎片描述符。
如下函数可用于填充分页描述符:
|
|
这会将第 i 个分页指向偏移 off 大小 size 的分页。同时更新 nr_frags 属性。
如果你想简单扩展已有碎片几个字节,增大 size 属性即可。
复制数据
因为非线性 SKB 带来的复杂性,看起来直接分析网络包中的数据并不容易,复制网络包数据到另一个缓冲也不容易。这不是问题。有两个函数可以轻松做到。
首先,第一个:
|
|
你需要提供:SKB,所需的数据的字节偏移量,所需的字节数量,和一个本地缓冲(如果所需的数据在非线性数据区域)。
你将得到指向数据的指针,或者 NULL 如果所需的数据偏移量和长度参数是无效的。该指针可能是如下二者之一:
- 直接指向那里的指针,如果所需的数据在
skb->data线性数据区域内。 - 否则是参数缓冲(buffer)的指针。
特别地,在发包路径上,分析网络包头部的代码就应该使用这个函数去读取、解释协议头部。netfilter 层就重重使用了该函数。
对于非协议头部的更大数据片,如下函数更为合适:
|
|
这将 SKB 中指定字节数量的、指定偏移量的数据复制到 to 缓冲中。这是用于复制 SKB 数据到内核缓冲,而不是复制到用户态空间。这有另一个函数:
|
|
这里,给定的 IOVEC 指向用户数据区域。其他参数跟上面的 skb_copy_bits() 函数一样。
文章作者 Leon Hwang
上次更新 2023-05-21
