书接上回 eBPF Talk: XDP 转发失败了,今回讲解为什么从物理网卡的驱动模式 XDP 程序 xdp_redirect() 到 veth 设备时一定要开启对端设备的 GRO 功能?
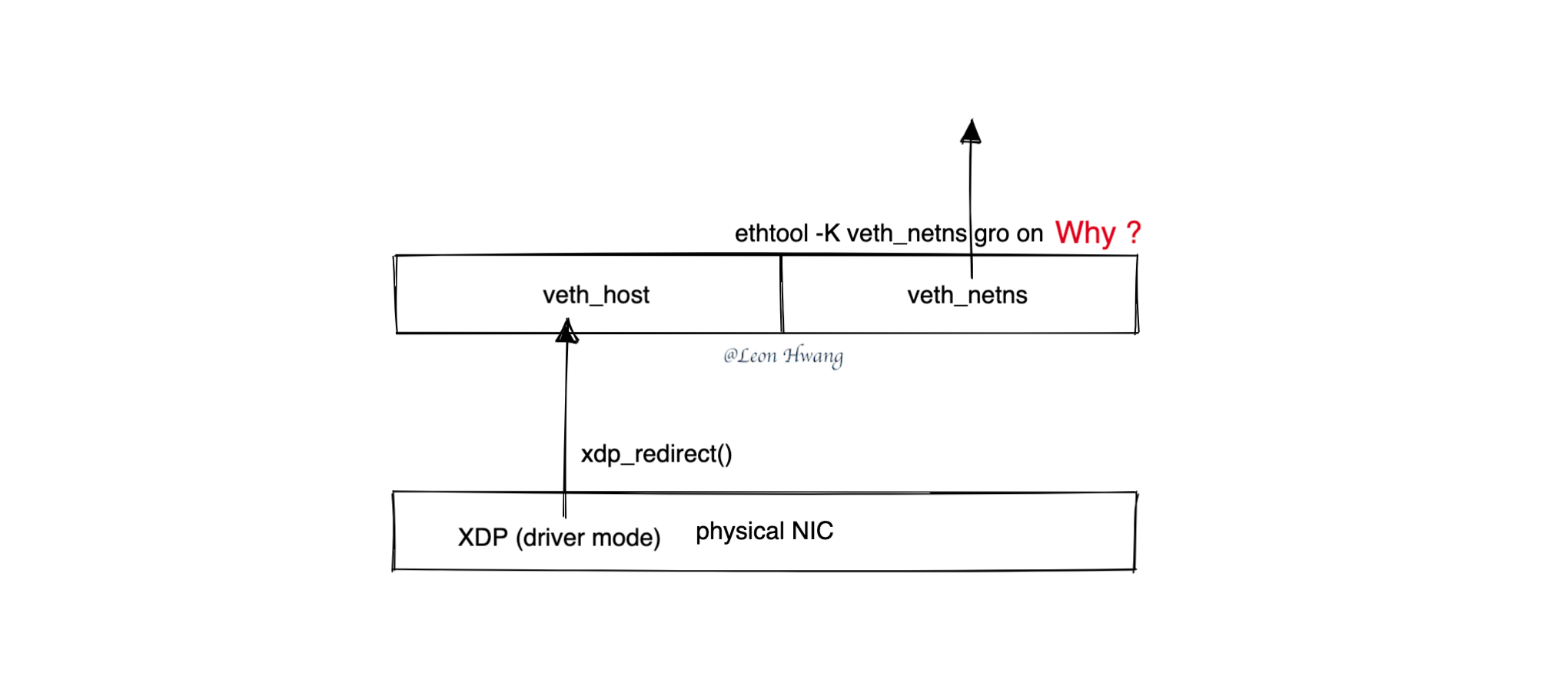
网络包 xdp_redirect() 转发到哪里去?
简单而言,网络包会进入 xdp_redirect() 目标 veth 设备的对端设备的某个 rxq->xdp_ring 里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
// ${KERNEL}/drivers/net/veth.c
static int veth_ndo_xdp_xmit(struct net_device *dev, int n, struct xdp_frame **frames, u32 flags)
|-->veth_xdp_xmit(dev, n, frames, flags, true);
static int veth_xdp_xmit(struct net_device *dev, int n, struct xdp_frame **frames, u32 flags, bool ndo_xmit) {
rcv = rcu_dereference(priv->peer);
rcv_priv = netdev_priv(rcv);
rq = &rcv_priv->rq[veth_select_rxq(rcv)]; // 根据 CPU ID 选择对应的 rxq
spin_lock(&rq->xdp_ring.producer_lock);
for (i = 0; i < n; i++) {
struct xdp_frame *frame = frames[i];
void *ptr = veth_xdp_to_ptr(frame);
if (unlikely(frame->len > max_len ||
__ptr_ring_produce(&rq->xdp_ring, ptr))) // 塞到 rq->xdp_ring 里
break;
nxmit++;
}
spin_unlock(&rq->xdp_ring.producer_lock);
ret = nxmit;
return ret;
}
|-->veth_select_rxq(rcv);
smp_processor_id() % dev->real_num_rx_queues;
|
上面代码片段的主要处理逻辑:
- 获取对端
veth 设备。
- 获取对端
veth 设备的私有数据。
- 根据 CPU ID 选择对端
veth 设备的接收队列。
- 将需要处理的
n 个网络包放入到选择的接收队列里的 xdp_ring。
注:veth_ndo_xdp_xmit() 处理的网络包类型是 struct xdp_frame * 而不是 struct sk_buff *。
插曲:veth 设备的 NAPI
网络包放入 xdp_ring 之后,什么时候会被捞出来处理呢?这就需要看看 NAPI 了。
且看启用 veth 设备的 NAPI 的处理过程。
执行 ethtool -K veth_xxx gro on 时,就启用了 veth 设备的 NAPI 功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
// ${KERNEL}/drivers/net/veth.c
.ndo_set_features = veth_set_features,
static int veth_set_features(struct net_device *dev, netdev_features_t features)
|-->veth_napi_enable()
|-->veth_napi_enable_range()
static int veth_napi_enable_range(struct net_device *dev, int start, int end)
{
struct veth_priv *priv = netdev_priv(dev);
int err, i;
for (i = start; i < end; i++) {
struct veth_rq *rq = &priv->rq[i];
netif_napi_add(dev, &rq->xdp_napi, veth_poll, NAPI_POLL_WEIGHT); // NAPI 调度使用的 poll 函数是 veth_poll
}
err = __veth_napi_enable_range(dev, start, end);
// ...
return err;
}
|-->__veth_napi_enable_range()
static int __veth_napi_enable_range(struct net_device *dev, int start, int end)
{
struct veth_priv *priv = netdev_priv(dev);
int err, i;
for (i = start; i < end; i++) {
struct veth_rq *rq = &priv->rq[i];
err = ptr_ring_init(&rq->xdp_ring, VETH_RING_SIZE, GFP_KERNEL); // 初始化 xdp_ring,网络包会放到这里
if (err)
goto err_xdp_ring;
}
for (i = start; i < end; i++) {
struct veth_rq *rq = &priv->rq[i];
napi_enable(&rq->xdp_napi); // 开启 NAPI 调度
rcu_assign_pointer(priv->rq[i].napi, &priv->rq[i].xdp_napi);
}
return 0;
err_xdp_ring:
for (i--; i >= start; i--)
ptr_ring_cleanup(&priv->rq[i].xdp_ring, veth_ptr_free);
return err;
}
|
以上代码片段的主要处理逻辑:
- 初始化
xdp_napi 和 xdp_ring。
- 将
xdp_napi 的 poll 函数设置为 veth_poll。
- 开启 NAPI 调度。
内核协议栈的 skb 从 veth 设备的哪里来?
当 veth_poll 函数被调用时,会将 xdp_ring 里的网络包 xdp_frame 捞出来,然后封装成 skb,然后调用网络协议栈的 napi_gro_receive() 函数进入到网络协议栈的 skb GRO 处理逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
|
veth_poll(struct napi_struct *napi, int budget) // ${KERNEL}/drivers/net/veth.c
|-->veth_xdp_rcv()
|-->veth_xdp_rcv_bulk_skb()
|-->skb = __xdp_build_skb_from_frame(); // ${KERNEL}/net/core/xdp.c
| |-->skb = build_skb_around(skb, hard_start, frame_size);
|-->napi_gro_receive(&rq->xdp_napi, skb); // ${KERNEL}/net/core/dev.c
|-->napi_skb_finish()
|-->gro_normal_one()
|-->gro_normal_list()
|-->netif_receive_skb_list_internal()
|-->__netif_receive_skb_list()
|-->...
|
以上代码片段的主要处理逻辑:
- 将
xdp_frame 从 xdp_ring 取出。
- 将
xdp_frame 封装成 skb。
- 将
skb 进行 NAPI GRO 处理。
- NAPI GRO 处理完毕之后,会进入到内核网络协议栈设备层及之后的处理流程。
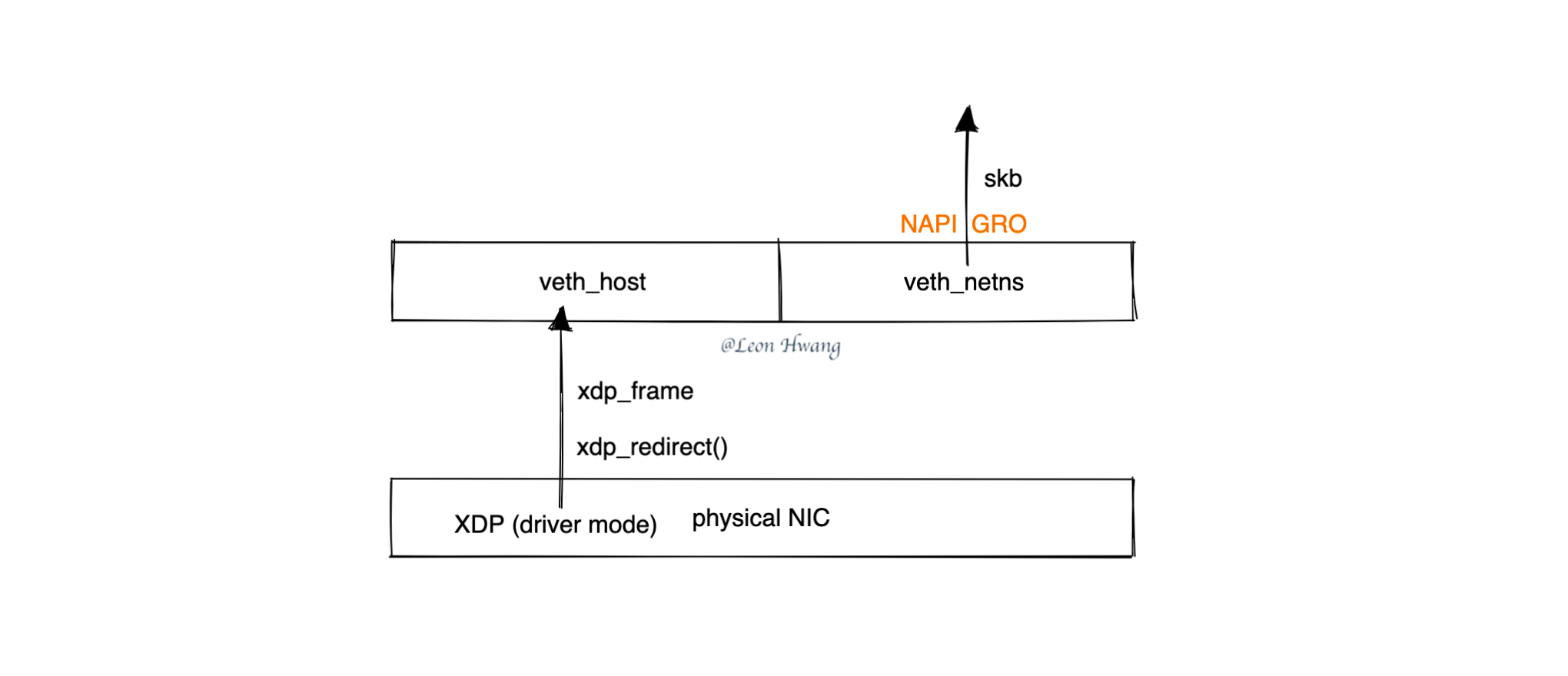
小结
veth 设备的 NAPI GRO 功能,是为了将从物理网卡过来的网络包 struct xdp_frame * 封装成内核协议栈的 struct sk_buff * (aka skb);之后,内核协议栈便可继续处理该 skb 了。

