eBPF Talk: tailcall 与 bpf2bpf【译】

文章目录
本文翻译自 Cilium 出品的 BPF and XDP Reference Guide,翻译了其中的 tailcall 和 bpf2bpf 部分。
tailcall:尾调用。bpf2bpf:BPF 到 BPF 函数调用。
tailcall
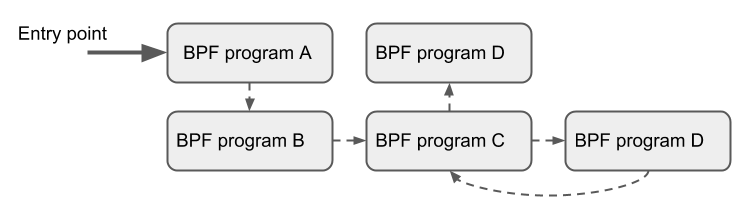
tailcall 可以看作允许一个 BPF 程序调用另一个程序的机制,而且该调用无需返回原程序。这样的调用并不像常规的函数调用,它实际由一个长跳转(long jump)来实现,并复用同一个栈帧(stack frame)。
这样的程序会各自独自进行校验。因此如果要在它们之间传数据,要么使用 per-CPU map 当作暂时缓冲,要么使用 skb 的 cb[] 区域(对于 tc 程序而言)。
只有相同类型的程序才能相互尾调用,而且它们需要使用同款 JIT 编译。因此,要么 JIT 编译的程序、要么只解释的程序可以相互调用,但不能混着来。
tailcall 涉及两个组件:程序数组 BPF_MAP_TYPE_PROG_ARRAY 和 bpf_tail_call()。BPF_MAP_TYPE_PROG_ARRAY 是一个 tailcall 专用的 map,需要由用户态程序填充 key/value;key 是 32 位无符号整型 uint32 的数组索引;value 是尾调用的 BPF 程序的文件描述符。bpf_tail_call() 帮助函数,其参数分别是上下文(context)、程序数组引用和数组索引。然后,内核直接将 tailcall 内联(inline)成特定的 BPF 指令。然而,在当下,该程序数组只能由用户态侧可写(BPF 程序不可写)。
当用户态写入文件描述符到程序数组时,内核查询其关联的 BPF 程序,并原子性地将程序指针替换到指定的程序数组槽位中。而在运行的时候,如果程序数组中给定 key 的槽位为空,内核就会“跳过 tailcall”并继续执行原有程序中 bpf_tail_call() 后面的指令。tailcall 是一个非常强大的工具,譬如可以通过多个 tailcall 来解析网络头部。在运行的时候,一些功能可以被原子性地添加进来,并因此变更 BPF 程序的执行行为。
bpf2bpf
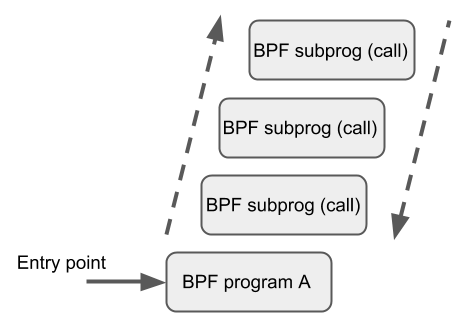
除了 BPF 帮助函数调用和 BPF 尾调用以外,最近添加到 BPF 核心基础架构的特性是 BPF 到 BPF 调用(bpf2bpf)。在该特性引入内核之前,典型的 BPF C 程序想要复用代码,就需要在头文件中使用 always_inline;以此让 LLVM 在编译、生成 BPF 对象文件时内联所有这些函数;但因此使得一个 always_inline 的函数在一个对象文件里重复多次,并导致对象文件大小极速膨胀:
|
|
该特性如此重要的主要原因是 BPF 程序加载器、校验器、解释器 和 JIT 等缺乏函数调用的支持。从 Linux 内核 4.16 和 LLVM 6.0 开始,该限制已解除;BPF 程序不再需要到处使用 always_inline 了。因此,上面 BPF 代码片段可以更自然地改写成:
|
|
x86_64 和 arm64 等主流 BPF JIT 编译器已支持 bpf2bpf,其它 JIT 编译器会在不久的将来跟进。bpf2bpf 带来了非常重要的性能优化,因为它极大地减小了生成的 BPF 代码大小,并因此对 CPU 指令缓存更加友好。
BPF 帮助函数的调用规约同样适用于 bpf2bpf,意味着 r1 到 r5 用于传递参数给被调用者、返回结果保存在 r0。通常而言,r1 到 r5 是暂存器,r6 到 r9 保留给调用之间使用。各自嵌套调用的调用帧最大数量是 8。调用者可以传递指针(比如调用者的栈帧)给被调用者,但不能反着来。
BPF JIT 编译器为每个函数生成各自的镜像(image),并在最后一轮的 JIT 处理中修复镜像里的函数调用地址。这已被证明所需的 JIT 变更最小,并能跟常规的 BPF 帮助函数调用同样对待 bpf2bpf。
组合使用 tailcall 和 bpf2bpf
直至内核 5.9,tailcall 和 bpf2bpf 之间是互斥的。使用 tailcall 的 BPF 程序不能享受更小的程序镜像大小和更快的加载时间等收益。Linux 内核 5.10 终于允许用户组合两个世界之最,增加了 BPF 子程序组合 tailcall 的能力。
尽管这次改进伴随着一些限制。组合使用这两个特性可能会导致内核栈溢出。为了搞明白这一点,看下组合使用 bpf2bpf 和 tailcall 的插图:
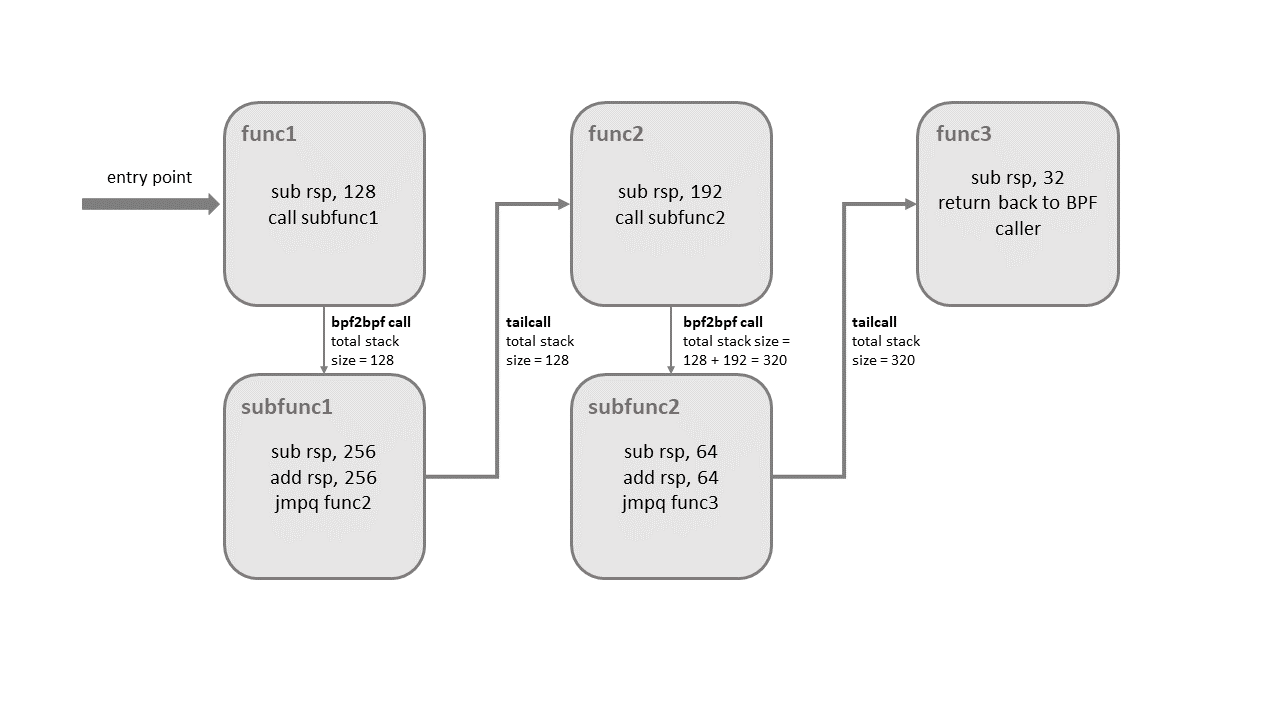
在真正进入目标程序之前,tailcall 会释放它所在的栈帧。如上图,如果在子函数内进行 tailcall,当 func2 程序执行时会使用函数(func1)栈帧。一旦最后的函数(func3)结束,前面所有的栈帧都会被释放掉,并将控制权给回到 BPF 程序调用者的调用者。
内核使用额外逻辑去处理这特性组合。贯穿整个调用链,每个子程序的栈大小上限为 256 字节(注:如果校验器检测到 bpf2bpf,主函数也会被当作子函数对待)。总之,在这限制下,BPF 程序调用链最多消耗 8KB 栈空间;由每个栈帧 256 字节乘以 tailcall 数量限制(33)计算得到。如果没有该限制,BPF 程序可以操作 512 字节栈大小,导致最大数量的 tailcall 总共消耗 16KB 大小;在某些 CPU 架构上会导致栈溢出。
译者注:这里的栈空间指的是内核线程栈空间,一般内核线程栈空间大小为 8KB。内核线程栈空间的大小取决于具体的 CPU 架构。
One more thing: 目前只有 x86-64 架构支持组合使用 tailcall 和 bpf2bpf。
文章作者 Leon Hwang
上次更新 2023-05-23
