本文翻译自 Assembly within! BPF tail calls on x86 and ARM,翻译了其中 tailcall 与 x86 部分,略过 arm 部分。
以下为译文。
最初我们学习编程的时候,我们就学习了 递归。较于其它东西,如带有重复代码的顺序结构,递归非常便于计算。例如著名的 Fibonacci 数 - Fn = Fn-1 + Fn-2。
后来,随着深入多线程编程,我们学到了一个事实:调用帧的 栈空间 是有限的。因而有两种使用递归计算 Fibonacci 数的办法:
1,okay 的办法:
1
2
3
4
5
6
7
8
9
10
11
|
// fib_okay.c
#include <stdint.h>
uint64_t fib(uint64_t n)
{
if (n == 0 || n == 1)
return 1;
return fib(n - 1) + fib(n - 2);
}
|
2,cool 的办法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// fib_cool.c
#include <stdint.h>
static uint64_t fib_tail(uint64_t n, uint64_t a, uint64_t b)
{
if (n == 0)
return a;
if (n == 1)
return b;
return fib_tail(n - 1, b, a + b);
}
uint64_t fib(uint64_t n)
{
return fib_tail(n, 1, 1);
}
|
如果我们能看下编译器生成的机器码,cool 的办法下翻译出一段漂亮且紧凑的指令序列:
声明:本文有较多的汇编。我们将看到 x86-64、arm64 和 BPF 架构的汇编代码。如果需要指导,我推荐如下资料:x86-64 Igor Zhirkov 写的 Low-Level Programming,arm64 Stephen Smith 写的 Programming with 64-Bit ARM Assembly Language,BPF 的请看 Linux kernel document。
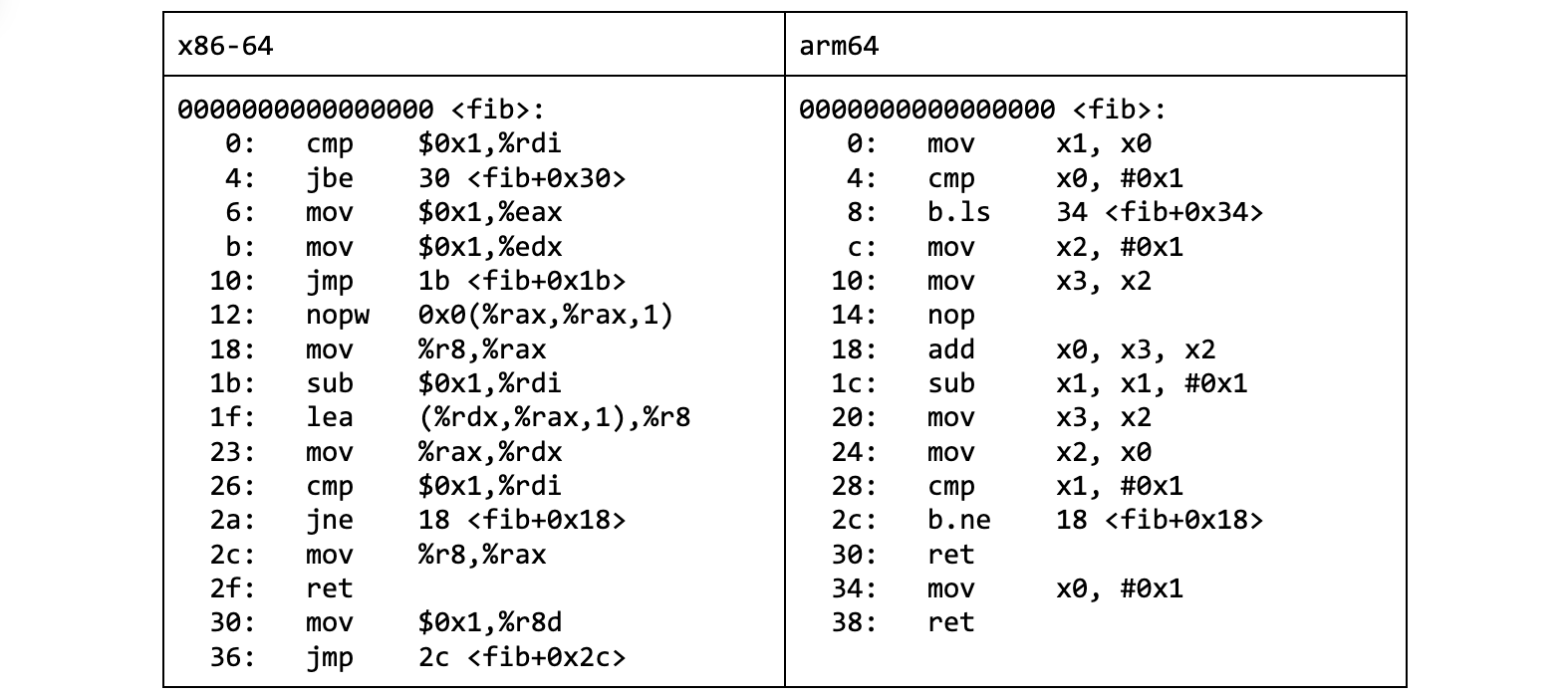
而 okay 的办法就令人失望了,它导致了 更多的指令。它简直是一团 basic blocks 意大利面条。

但更重要的是,它并没有避免掉 x86 call 指令。
1
2
3
4
|
$ objdump -d fib_okay.o | grep call
10c: e8 00 00 00 00 call 111 <fib+0x111>
$ objdump -d fib_cool.o | grep call
$
|
这就导致一个重要结果:随着 fib 递归地调用自己,栈就一直增长。我们可以通过 调试器 观测到它。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
$ gdb --quiet --batch --command=trace_rsp.gdb --args ./fib_okay 6
Breakpoint 1 at 0x401188: file fib_okay.c, line 3.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
n = 6, %rsp = 0xffffd920
n = 5, %rsp = 0xffffd900
n = 4, %rsp = 0xffffd8e0
n = 3, %rsp = 0xffffd8c0
n = 2, %rsp = 0xffffd8a0
n = 1, %rsp = 0xffffd880
n = 1, %rsp = 0xffffd8c0
n = 2, %rsp = 0xffffd8e0
n = 1, %rsp = 0xffffd8c0
n = 3, %rsp = 0xffffd900
n = 2, %rsp = 0xffffd8e0
n = 1, %rsp = 0xffffd8c0
n = 1, %rsp = 0xffffd900
13
[Inferior 1 (process 50904) exited normally]
$
|
然而 cool 的办法下则没有使用栈。
1
2
3
4
5
6
7
8
|
$ gdb --quiet --batch --command=trace_rsp.gdb --args ./fib_cool 6
Breakpoint 1 at 0x40118a: file fib_cool.c, line 13.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
n = 6, %rsp = 0xffffd938
13
[Inferior 1 (process 50949) exited normally]
$
|
call 指令哪里去了?
聪明的编译器将函数体里最后的函数调用转换成了一个常规跳转(regular jump)。为什么允许这么做呢?
我们谈论的是函数体里最后一条指令。只要返回(return)了,调用者栈帧就会被销毁。所以,当我们复用它当作被调用者的 栈帧 时,为什么还要保留它呢?
这个优化,即 尾调用消除,令我们在 Fibonacci cool 办法实现中不需要用到函数调用。有且仅有一个调用去消除 - 就是最后那个。
一旦应用,调用变跳转(循环)。如果汇编不是你的第二语言,使用 Ghidra 反编译查看 fib_cool.o 对象文件去查看这种转变:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
long fib(ulong param_1)
{
long lVar1;
long lVar2;
long lVar3;
if (param_1 < 2) {
lVar3 = 1;
}
else {
lVar3 = 1;
lVar2 = 1;
do {
lVar1 = lVar3;
param_1 = param_1 - 1;
lVar3 = lVar2 + lVar1;
lVar2 = lVar1;
} while (param_1 != 1);
}
return lVar3;
}
|
这就是我们想要的。不仅生成的机器码更短,也因不用调用而变得更快(对比 okay 办法下的 profile)。
不过我不是 性能隐者,且本文不是关于编译器优化的。所以为什么我要告诉你这些呢?

BPF tailcall
尾调用消除的概念以它自己的方式进入到 BPF 世界,尽管不是你可能预期的方式。对,当使用 -target bpf 时,LLVM 编译器在构建时消除了末尾的函数调用。这个转换发生在 IR 层面,所以它不涉及编译器后端。这能够节省你几个 bpf2bpf 函数调用,你可以看看 BPF 汇编里的 call -N 指令。
然而,当我们在 BPF 语境里讨论 tailcall 时,我们通常会想到其它一些东西。且这是一个 BPF JIT 编译器内置的专为 串联 BPF 程序 而生的机制。
我们第一次接触 tailcall 是在构建我们的 基于 XDP 的网络包处理流水线 的时候。多得它,我们才能够将处理逻辑拆分成多个 XDP 程序;每个程序只做一件事。
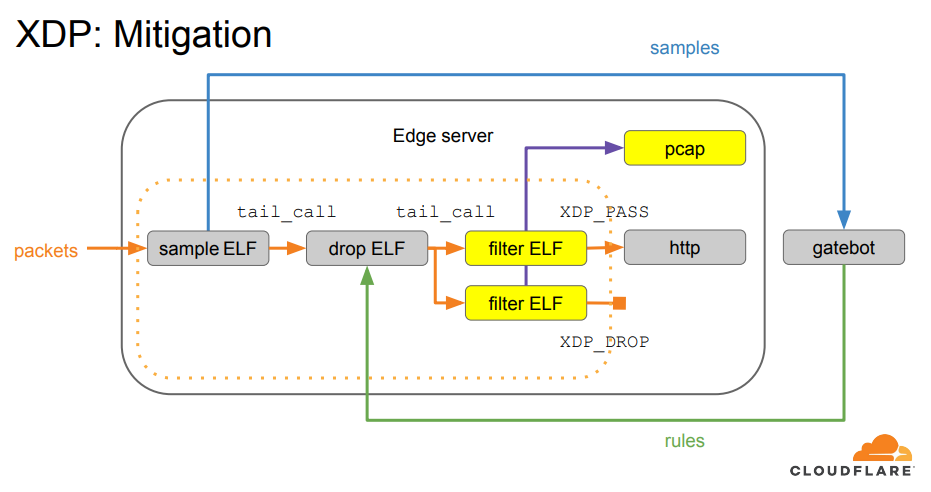
XDP based DDoS Mitigation
自那时起我们就一直使用 tailcall。但它们有它们的税收。直到最近,同样的 XDP 程序,在arm64 上就不能同时使用 tailcall 和 bpf2bpf 了。
为什么?在得到答案之前,让我们深挖一下 tailcall 如何运转的。
尾调用是尾调用是尾调用
BPF 通过 BPF 代码里调用的 bpf_tail_call() 揭示了 tailcall 机制。所以,我们不能直接知道会调用哪个 BPF 程序。不过,我们传给它一个持有 BPF 程序引用的 BPF map(一个容器、BPF_MAP_TYPE_PROG_ARRAY),和一个索引。
1
2
3
4
5
6
7
8
9
10
11
12
|
long bpf_tail_call(void *ctx, struct bpf_map *prog_array_map, u32 index)
Description
This special helper is used to trigger a "tail call", or
in other words, to jump into another eBPF program. The
same stack frame is used (but values on stack and in reg‐
isters for the caller are not accessible to the callee).
This mechanism allows for program chaining, either for
raising the maximum number of available eBPF instructions,
or to execute given programs in conditional blocks. For
security reasons, there is an upper limit to the number of
successive tail calls that can be performed.
|
bpf-helpers(7) man page
第一眼看去,这看着有点想 execve(2) 系统调用。它很容易被误解为在当前程序上下文里去执行新程序的方式。Cilium 项目出品的 BPF and XDP Reference Guide 文档里指出:
tailcall 可以看作允许一个 BPF 程序调用另一个程序的机制,而且该调用无需返回原程序。这样的调用并不像常规的函数调用,它实际由一个长跳转(long jump)来实现,并复用同一个栈帧(stack frame)。
但是,一旦将 BPF 函数调用 混起来使用,tailcall 机制其实就是尾调用消除的一种实现,而不是程序替换的程序:
在真正进入目标程序之前,tailcall 会释放它所在的栈帧。如上图,如果在子函数内进行 tailcall,当 func2 程序执行时会使用函数(func1)栈帧。一旦最后的函数(func3)结束,前面所有的栈帧都会被释放掉,并将控制权给回到 BPF 程序调用者的调用者。
唉,来个语法上的小惊喜。看下 下面一段使用 bpf_tail_call() 的 BPF 代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__uint(max_entries, 1);
__uint(key_size, sizeof(__u32));
__uint(value_size, sizeof(__u32));
} bar SEC(".maps");
SEC("tc")
int serve_drink(struct __sk_buff *skb __unused)
{
return 0xcafe;
}
static __noinline
int bring_order(struct __sk_buff *skb)
{
bpf_tail_call(skb, &bar, 0);
return 0xf00d;
}
SEC("tc")
int server1(struct __sk_buff *skb)
{
return bring_order(skb);
}
SEC("tc")
int server2(struct __sk_buff *skb)
{
__attribute__((musttail)) return bring_order(skb);
}
|
上面有两个看着没什么区别的 BPF 程序 - server1() 和 server2().它们都调用同一个 BPF 函数 bring_order()。该函数尾调用了 serve_drink() 程序,假设 [bar[0] map 条目指向它。
它们的返回值都一样吗?答案如下 - 不,他们没有。server1返回 🍔,而 server2 发挥 ☕。为什么会这样?
需要注意的第一个东西(first thing)是 tailcall 释放(unwind)的仅是当前函数栈帧。函数里的 bpf_tail_call() 代码从未执行,即使指定的尾调用成功了(map 条目存在,且未触及尾调用限制)。
当尾调用结束,控制权回到了发起尾调用的调用者函数手上。应用到我们的例子上,两个程序的控制流都是 serverX() --> bring_order() --> bpf_tail_call() --> serve_drink() -return-> serverX()。
需要注意的第二个东西是,编译器并不知道 bpf_tail_call() 会改变控制流。因此,无知的编译器优化了代码:tailcall 之后会继续执行。

server1() 和 server2() 的调用图(call graph)都一样,但因构建时(build time)优化而返回值不一样。
在这个例子里,编译器认为采用从 bring_order() 返回给 server1() 的常量是没问题的。如果没有检查 生成的 BPF 汇编,可能会带给我们惊喜。
我们可以 强行令编译器 musttail 去尾调用 bring_order()。通过这种方式,我们可以保证无论 bring_order() 返回什么都被当作 server2() 程序结果。
🛈 一般规则:为了最小惊喜结果,当调用一个包含 tailcall 的函数时,使用 musttail 属性。
bpf_tail_call() 底层是如何工作的?是时候深挖了。

x86-64 上的 tailcall
在 x86-64 BPF JIT 编译之后,bpf_tail_call() 会被翻译成什么呢?x86-64 上的实现是如何确保不会永远地坠入 tailcall 循环的?
为了解密,我们需要先拼凑几个东西。
第一个是 BPF JIT 编译器源代码,arch/x86/net/bpf_jit_comp.c。源代码里有不少有用的注释。我们只需关心 JIT 里的以下调用链:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// ${KERNEL}/arch/x86/net/bpf_jit_comp.c
do_jit()
|-->emit_prologue()
|-->push_callee_regs()
for (i = 1; i <= insn_cnt; i++, insn++) {
switch (insn->code) {
case BPF_JMP | BPF_CALL:
/* emit function call */
case BPF_JMP | BPF_TAIL_CALL:
emit_bpf_tail_call_direct()
case BPF_JMP | BPF_EXIT:
/* emit epilogue */
}
}
|
有时是很难从编译器源代码中构想生成的指令流。因此,我们需要观察 JIT 编译器的输入(BPF 指令)和输出(x86-64 指令)。
我们可以使用 bpftool prog dump 来观察已加载(loaded) BPF 程序的 BPF 指令和 x86-64 指令。然而,首先我们必须填充用于尾调用跳表(jump table)的 BPF map。否则,我们可能看不到尾调用跳转。
这是因为 某次优化:当加载时已知程序数组索引时,就使用指令补丁(instruction patching)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
# bpftool prog loadall ./tail_call_ex1.o /sys/fs/bpf pinmaps /sys/fs/bpf
# bpftool map update pinned /sys/fs/bpf/jmp_table key 0 0 0 0 value pinned /sys/fs/bpf/target_prog
# bpftool prog dump xlated pinned /sys/fs/bpf/entry_prog
int entry_prog(struct __sk_buff * skb):
; bpf_tail_call(skb, &jmp_table, 0);
0: (18) r2 = map[id:24]
2: (b7) r3 = 0
3: (85) call bpf_tail_call#12
; return 0xf00d;
4: (b7) r0 = 61453
5: (95) exit
# bpftool prog dump jited pinned /sys/fs/bpf/entry_prog
int entry_prog(struct __sk_buff * skb):
bpf_prog_4f697d723aa87765_entry_prog:
; bpf_tail_call(skb, &jmp_table, 0);
0: nopl 0x0(%rax,%rax,1)
5: xor %eax,%eax
7: push %rbp
8: mov %rsp,%rbp
b: push %rax
c: movabs $0xffff888102764800,%rsi
16: xor %edx,%edx
18: mov -0x4(%rbp),%eax
1e: cmp $0x21,%eax
21: jae 0x0000000000000037
23: add $0x1,%eax
26: mov %eax,-0x4(%rbp)
2c: nopl 0x0(%rax,%rax,1)
31: pop %rax
32: jmp 0xffffffffffffffe3 // bug? 🤔
; return 0xf00d;
37: mov $0xf00d,%eax
3c: leave
3d: ret
|
注意了,bpftool prog dump jited 看到的尾调用跳转的目标地址是没有任何意义的。为了发现真正的跳转目标地址,我们必须深入内核内存。在我们在 /proc/kallsyms 中找到 JIT 后的 BPF 程序地址后,gdb 派上用场。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# tail -2 /proc/kallsyms
ffffffffa0000720 t bpf_prog_f85b2547b00cbbe9_target_prog [bpf]
ffffffffa0000748 t bpf_prog_4f697d723aa87765_entry_prog [bpf]
# gdb -q -c /proc/kcore -ex 'x/18i 0xffffffffa0000748' -ex 'quit'
[New process 1]
Core was generated by `earlyprintk=serial,ttyS0,115200 console=ttyS0 psmouse.proto=exps "virtme_stty_c'.
#0 0x0000000000000000 in ?? ()
0xffffffffa0000748: nopl 0x0(%rax,%rax,1)
0xffffffffa000074d: xor %eax,%eax
0xffffffffa000074f: push %rbp
0xffffffffa0000750: mov %rsp,%rbp
0xffffffffa0000753: push %rax
0xffffffffa0000754: movabs $0xffff888102764800,%rsi
0xffffffffa000075e: xor %edx,%edx
0xffffffffa0000760: mov -0x4(%rbp),%eax
0xffffffffa0000766: cmp $0x21,%eax
0xffffffffa0000769: jae 0xffffffffa000077f
0xffffffffa000076b: add $0x1,%eax
0xffffffffa000076e: mov %eax,-0x4(%rbp)
0xffffffffa0000774: nopl 0x0(%rax,%rax,1)
0xffffffffa0000779: pop %rax
0xffffffffa000077a: jmp 0xffffffffa000072b
0xffffffffa000077f: mov $0xf00d,%eax
0xffffffffa0000784: leave
0xffffffffa0000785: ret
# gdb -q -c /proc/kcore -ex 'x/7i 0xffffffffa0000720' -ex 'quit'
[New process 1]
Core was generated by `earlyprintk=serial,ttyS0,115200 console=ttyS0 psmouse.proto=exps "virtme_stty_c'.
#0 0x0000000000000000 in ?? ()
0xffffffffa0000720: nopl 0x0(%rax,%rax,1)
0xffffffffa0000725: xchg %ax,%ax
0xffffffffa0000727: push %rbp
0xffffffffa0000728: mov %rsp,%rbp
0xffffffffa000072b: mov $0xcafe,%eax
0xffffffffa0000730: leave
0xffffffffa0000731: ret
#
|
最后,JIT 编译器使用的 BPF 寄存器和硬件寄存器之间的 对照表 是非常有用的。
| BPF |
x86-64 |
| r0 |
rax |
| r1 |
rdi |
| r2 |
rsi |
| r3 |
rdx |
| r4 |
rcx |
| r5 |
r8 |
| r6 |
rbx |
| r7 |
r13 |
| r8 |
r14 |
| r9 |
r15 |
| r10 |
rbp |
| internal |
r9-r12 |
如今,我们准备搞明白使用 tailcall 时发生了什么。

本质上,bpf_tail_call() 就是跳转另一个函数、复用当前栈帧的跳转。它就像一个常规优化的尾调用,但有点点绕。
因为 BPF 安全必须保证 BPF 程序执行会结束、没有栈溢出,所以尾调用次数有限制(MAX_TAIL_CALL_CNT = 33)。
在 BPF 程序之间计数尾调用不是加载时的事情。跳表(jump table)(BPF 程序数组)的内容可以在程序被校验后被变更。我们唯一选项就是在运行时跟踪尾调用。这就是 bpf_tail_call() 帮助函数 JIT 后的代码检查并更新 tail_call_cnt 计数器的原因。
如我们所见,通过 rax 寄存器(BPF r0 寄存器),更新后的计数器会从一个 BPF 程序传到另一个,从一个 BPF 函数传到另一个。
幸运的是,x86-64 调用规约规定 rax 寄存器不参与传递函数参数,但相反地会保存函数返回值。JIT 就可以用它来传递额外的、隐藏的参数。
然后,函数体可以随意使用 r0/rax 寄存器。这就解释了在跳转到另一个程序后需要立刻将 rax 传递的 bpf_tail_cnt 保存到栈上。之后 bpf_tail_call() 就可以从栈上已知位置加载值。
结合每个 bpf_tail_call() 调用 生成的代码和 BPF 函数序言 (BPF function prologue),就可以在多个 BPF 程序之间跟踪尾调用计数。
但是,如果我们的 BPF 程序割裂成好几个 BPF 函数,每个函数都有其栈帧呢?如果这些函数都有 tailcall 呢?接着尾调用技术该如何跟踪呢?
混合使用 bpf2bpf 和 tailcall
受内部实现影响,当谈及函数和函数调用时,BPF 有其自己的术语。函数调用已称作 BPF 到 BPF 调用。对应的,BPF 代码中的主函数/入口函数叫作“程序”,而其它函数就是“子程序”。
每个子程序都会为本地状态分配直至函数返回都会维持的栈帧。自然地,嵌套的 BPF 子程序调用构成一个调用链。就像用户态的嵌套函数调用。
在 BPF 子程序中也是可以使用 tailcall 的。非常有成效地,这是个将调用链扩展到其它 BPF 程序及其子程序的机制。
如果我们不能跟踪调用链有多长、每个函数使用的栈空间有多少,我们就会陷入 栈溢出 的风险中。我们不能让其发生,所以 BPF 强行限制了 tailcall:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
static int check_max_stack_depth(struct bpf_verifier_env *env)
{
…
/* protect against potential stack overflow that might happen when
* bpf2bpf calls get combined with tailcalls. Limit the caller's stack
* depth for such case down to 256 so that the worst case scenario
* would result in 8k stack size (32 which is tailcall limit * 256 =
* 8k).
*
* To get the idea what might happen, see an example:
* func1 -> sub rsp, 128
* subfunc1 -> sub rsp, 256
* tailcall1 -> add rsp, 256
* func2 -> sub rsp, 192 (total stack size = 128 + 192 = 320)
* subfunc2 -> sub rsp, 64
* subfunc22 -> sub rsp, 128
* tailcall2 -> add rsp, 128
* func3 -> sub rsp, 32 (total stack size 128 + 192 + 64 + 32 = 416)
*
* tailcall will unwind the current stack frame but it will not get rid
* of caller's stack as shown on the example above.
*/
if (idx && subprog[idx].has_tail_call && depth >= 256) {
verbose(env,
"tail_calls are not allowed when call stack of previous frames is %d bytes. Too large\n",
depth);
return -EACCES;
}
…
}
|
栈深度(stack depth)在加载时由 BPF 校验器计算得到,我们仍然需要在运行时保持计数尾调用跳转;即使涉及子程序。
这意味着,我们必须从一个 BPF 子程序到另一个子程序之间传递尾调用计数,就像 tailcall 时的做法,所以我们再一次通过 rax 寄存器传值。

🛈 简单起见,例子中的 BPF 代码不在栈上分配任何东西。我建议你检查一下当你 加一些局部变量 时 JIT 后的机器汇编代码变化;只需保证编译器不将它们优化掉。
为了成功,我们需要:
① 在 call 子程序前将保存在栈上的尾调用计数加载到 rax 寄存器中,
② 调整子程序序言(prologue),使其不要像主程序一样重置 rax,
③ 将传过来的尾调用计数保存到子程序的栈上,以防 bpf_tail_call() 帮助函数用到。
子程序中的 bpf_tail_call() 就会:
④ 从栈上加载尾调用计数,
⑤ 释放(unwind)BPF 栈,当实际上会保留当前子程序栈帧,
⑥ 跳转到目标 BPF 程序。
至此,我们已看到拼图碎片拼凑一起使得 tailcall 在 x86-64 上安全地工作起来。
略过 tailcall on arm64 部分。
总结
从递归到 BPF JIT。我们是如何做到的?不重要。重要的是这个过程。
在这过程中,我们揭示了 tailcall 背后的秘密,并希望能抑制住你的学习底层编程(low-level programming)的渴望;至少是今天。
剩下的就是做下来等待我们的工作成果。通过 GDB 在 VM 上挂钩子,我们能够观测到 BPF 程序是如何调用 BPF 函数的、是如何从那尾调用另一个 BPF 程序的:
https://demo-gdb-step-thru-bpf.pages.dev/
直到下一次🖖。

