eBPF Talk: 使用 AF_XDP 加速网络【译】

文章目录
本文翻译自 2018 年的 LWN: Accelerating networking with AF_XDP。
以下为译文。
Linux 网络栈不缺乏特性,且对于大部分使用场景都有不错的性能表现。不过,随着网络的高速发展,对网络栈的要求越来越高;导致大部分有高性能要求的用户走向摆脱内核限制的非常专业的用户态网络实现。高速数据通路(XDP)的努力尝试赢回他们,至今有所成效。随着 Björn Töpel 发布的 AF_XDP 补丁集合,另一块 XDP 拼图正进入大众视野。
XDP 的初衷是尽可能摆脱网络栈。虽然网络栈有非常高的灵活性,XDP 就是围绕着最最最基本的网络包传输而生。当需要处理或者修改一个网络包时,XDP 将提供用户实现的干这活的 BPF 程序的钩子。最终结果包含了极大的灵活性,和相关 man page 上的 ”一些所需汇编“ 的消耗。对于那些关心网络包处理消耗的每纳秒(需要指出的是:4.17 内核将带上几个将 BPF JIT 编译器生成的代码缩减 5% 的辛勤努力)、设法将所有拼图碎片拼凑到一起的用户而言,这是非常值得的。
在 早期的 XDP 中,将 BPF 程序加载进网卡设备驱动中,用于尽可能快地丢弃网络包。那可能不是最令人兴奋的应用,但对于需要抵御 DDoS 攻击的网站而言这是非常有用的特性。自那时起,XDP 就获得处理简单路由(将网络包从它到来的网卡重新发送出去)的能力,并且,对于某些硬件,还能够将 BPF 程序下载(offload)到硬件驱动里。
尽管说,在网卡驱动里能做的有限;此时,AF_XDP 就能够连接 XDP 通路和用户态空间。它可以被认为是类似于 AF_PACKET 地址簇的存在,因此它能够以最小处理将网络包发往/接收自应用,但该接口是给应用做网络包优先级处理而不是为了方便。所以,再一次强调,为了使用它,一些汇编是很有必要的。
那汇编始于使用 AF_XDP 地址簇的 socket() 调用;那会给出一个 socket 文件描述符(file descriptor)用于移动网络包。首先,然而,在用户态空间创建一个叫做 “UMEM” 的数组是重要的。它是一串连续的内存块,被分割为相等大小的”帧“(帧的实际大小由调用者指定);每个帧都能够储存一个独立的网络包。就它自己而言,UMEM 看着有点无聊:

在应用分配内存之后,该数组就通过 setsockopt() 系统调用的 XDP_UMEM_REG 命令进行注册。
数组里的每一帧都有一个名为 ”描述符“ 的整数索引。为了使用那些描述符,应用程序通过 setsockopt() 系统调用的 XDP_UMEM_FILL_QUEUE 命令创建一个名为 fill queue 的环形缓冲区。而后该队列就能通过 mmap() 映射到用户态空间内存。内核通过添加一个帧描述符到 fill queue 的方式将接收到的网络包放到 UMEM 数组的指定帧中,应用程序就能够从中获取网络包。
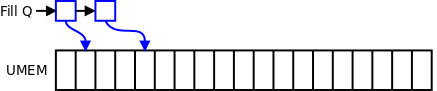
一旦描述符进入了 fill queue,内核就拥有了它(及其关联的 UMEM 帧)。应用程序要拿回一个描述符(关联的帧中带有一个新的网络包),就需要通过 setsockopt() 系统调用的 XDP_RX_QUEUE 创建另一个队列(receive queue)。它也是一个映射到用户态空间的环形缓冲区;一旦一个帧中填充了一个网络包,它的描述符就要被挪到 receive queue 中。poll() 系统调用就可以用来等待到达 receive queue 的网络包。
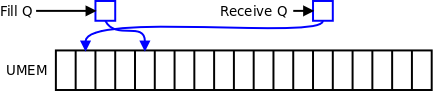
一个类似的故事同样存在于发包侧。应用程序通过 XDP_TX_QUEUE 命令创建 transmit queue,并映射到用户态空间;将需要发送的网络包的描述符放到 transmit queue 中。sendmsg() 系统调用告诉内核,一个或多个描述符已准备好发送。(通过 XDP_UMEM_COMPLETION 创建的)completion queue 在网络包发送之后接收它们的描述符。全景图如下:
所有的数据结构都是为了在用户态空间和内核之间 zero-copy 移动而设计,尽管在当前补丁中还没有实现。它也允许不用复制就将接收到的网络包发送出去,因为任何描述符都可以用来发送或者接收。
UMEM 数组可以在多个进程之间共享。如果一个进程想要创建一个绑定旧有 UMEM 的 AF_XDP socket,只需要使用 bind() 绑定它的 socket 文件描述符和 UMEM 宿主的文件描述符;后一个文件描述符保存在 bind() 的第二个参数 struct sockaddr_xdp 中。无论多少个进程共享 UMEM,一个 UMEM 都只有一个 fill queue 和一个 completion queue;而每个进程必须维护自己的 transmit queue 和 receive queue。换言之,在多进程环境中,一个进程(或者线程)将专门用于管理 UMEM 帧,同时其它每个进程(或者线程)都用于处理网络包。
有点绕的是,内核是如何为每个接收的网络包选择 receive queue 的。该拼图有两块碎片。第一块是类型为 BPF_MAP_TYPE_XSKMAP 的 bpf map。该 bpf map 是一个数组,数组中的每个槽位都是 AF_XDP socket 对应的文件描述符。绑定了 UMEM 的进程通过 bpf() 系统调用将文件描述符保存到 bpf map 中;当然,实际上保存的是应用程序不可见的内核内部指针。另一块碎片是加载到驱动的 BPF 程序,用于分类进来的网络包,并且将它们送到 bpf map 中;这就是将网络包放入到所选的 bpf map 条目对应 AF_XDP socket 的 receive queue 中。
没有 bpf map 和 BPF 程序的话,AF_XDP socket 就无法接收网络包。这就说明一些汇编是必要的。
最后一块碎片是通过 bind() 系统调用将 socket 绑定到指定的网卡,且可能是网卡里的某个硬件网络包队列。网卡本身就可配置成将网络包送到那队列,如果 AF_XDP socket 背后的程序可以处理。
期望的最终结果是,有一个结构体能够通过用户态空间代码尽可能使用硬件且最少使用内核地进行高效的网络包管理。尽管说,还需要一些努力才能做到。zero-copy 代码就是其中之一;对于高性能场景而言,在内核和用户态空间之间复制网络包是致命的。另一个努力是 Jesper Dangaard Brouer 开发的 XDP redirect 补丁包;它允许 XDP 程序将网络包直接送到指定 AF_XDP socket。驱动的支持也是有必要的;目前有几个 Intel 网卡正往主线靠拢。
如果一切按计划进行,将可以比主线内核网络包更高频率地处理网络包。该功能面向的不是多数开发者,而是曾经在用户态空间做网络栈的开发者。这是一个非常有趣的信号:用到 BPF 虚拟机的功能都将变得非常灵活。
文章作者 Leon Hwang
上次更新 2023-05-23
