通过学习 eBPF Talk: AF_XDP,我们掌握了 AF_XDP 的那些基础知识。
提问:对于如下高性能场景,在网卡收到网络包后,该网络包会被哪个 AF_XDP socket 处理呢?
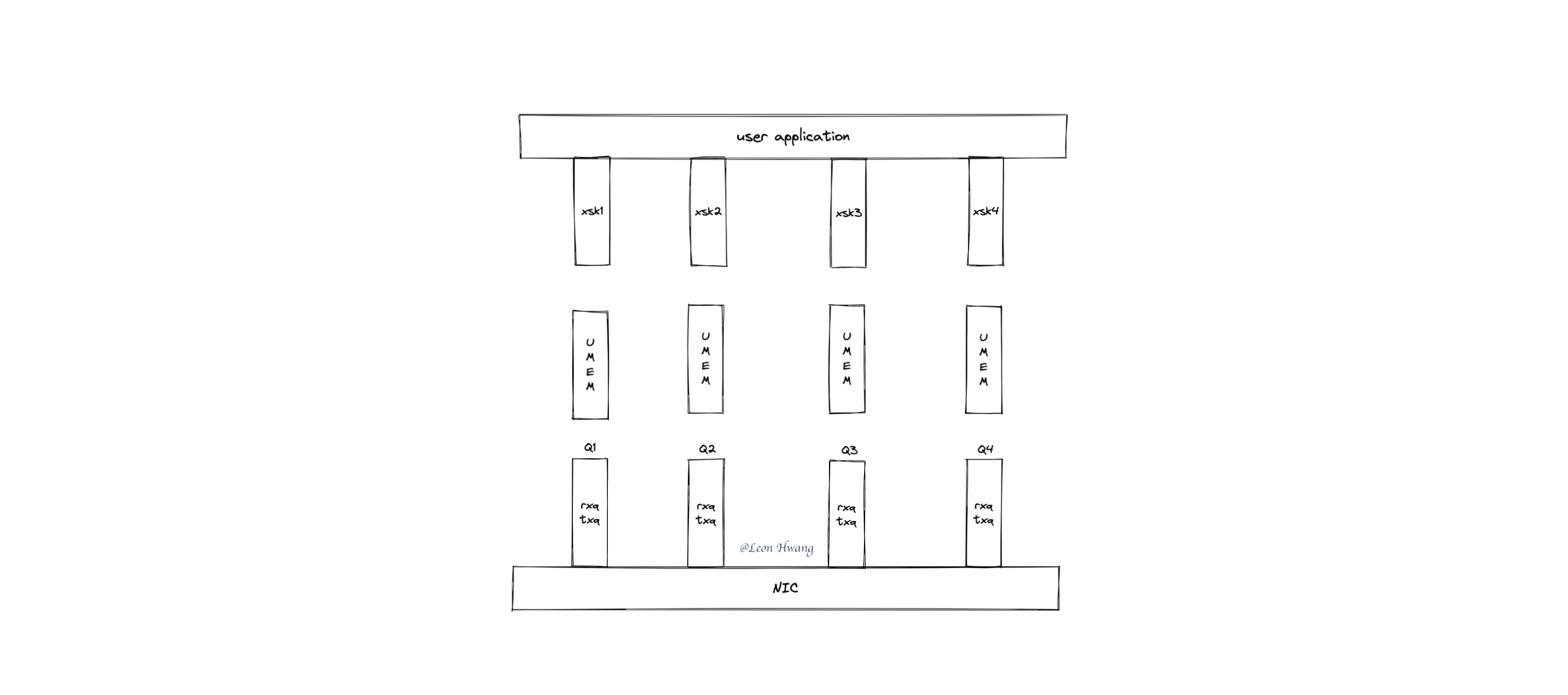
- 该网卡独占一个 XDP 程序。
- 该 XDP 程序独占一个 BPF_MAP_TYPE_XSKMAP bpf map。
- 用户态应用程序为每个 queue 创建一对 UMEM 和 AF_XDP socket。
- 使用
ethtool ntuple 在网卡里进行 RSS。
本文参考的用户态 Go 库为 asavie/xdp。
创建 AF_XDP socket 及其 UMEM
略过 AF_XDP socket 创建过程,直接看下 UMEM 是如何创建出来的吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
// ${asavie/xdp}/xdp.go
func NewSocket(Ifindex int, QueueID int, options *SocketOptions) (xsk *Socket, err error) {
//...
xsk = &Socket{fd: -1, ifindex: Ifindex, options: *options}
xsk.fd, err = syscall.Socket(unix.AF_XDP, syscall.SOCK_RAW, 0)
// ...
xsk.umem, err = syscall.Mmap(-1, 0, options.NumFrames*options.FrameSize,
syscall.PROT_READ|syscall.PROT_WRITE,
syscall.MAP_PRIVATE|syscall.MAP_ANONYMOUS|syscall.MAP_POPULATE)
// ...
xdpUmemReg := unix.XDPUmemReg{
Addr: uint64(uintptr(unsafe.Pointer(&xsk.umem[0]))),
Len: uint64(len(xsk.umem)),
Size: uint32(options.FrameSize),
Headroom: 0,
}
var errno syscall.Errno
var rc uintptr
rc, _, errno = unix.Syscall6(syscall.SYS_SETSOCKOPT, uintptr(xsk.fd),
unix.SOL_XDP, unix.XDP_UMEM_REG,
uintptr(unsafe.Pointer(&xdpUmemReg)),
unsafe.Sizeof(xdpUmemReg), 0)
// ...
sa := unix.SockaddrXDP{
Flags: DefaultSocketFlags,
Ifindex: uint32(Ifindex),
QueueID: uint32(QueueID),
}
if err = unix.Bind(xsk.fd, &sa); err != nil {
xsk.Close()
return nil, fmt.Errorf("syscall.Bind SockaddrXDP failed: %v", err)
}
// ...
return xsk, nil
}
|
如上代码片段的主要处理逻辑如下:
- 创建 AF_XDP socket。
- 使用
mmap 创建出 UMEM 所使用的内存。
- 将 UMEM 绑定到 AF_XDP socket。
- 将 AF_XDP socket 绑定到网卡的指定队列(
QueueID)。
UMEM 绑定 AF_XDP socket
将 UMEM 绑定 AF_XDP socket 的系统调用是: unix.Syscall6(syscall.SYS_SETSOCKOPT, uintptr(xsk.fd), unix.SOL_XDP, unix.XDP_UMEM_REG, uintptr(unsafe.Pointer(&xdpUmemReg)), unsafe.Sizeof(xdpUmemReg), 0)。
直接看下内核源代码的处理逻辑吧。
1
2
3
4
5
6
7
8
|
xsk_setsockopt() // ${KERNEL}/net/xdp/xsk.c
|-->umem = xdp_umem_create(&mr); // ${KERNEL}/net/xdp/xdp_umem.c
| |-->umem = kzalloc(sizeof(*umem), GFP_KERNEL);
| |-->xdp_umem_reg(umem, mr);
| |-->xdp_umem_account_pages(umem);
| |-->xdp_umem_pin_pages(umem, (unsigned long)addr);
| |-->xdp_umem_addr_map(umem, umem->pgs, umem->npgs);
|-->WRITE_ONCE(xs->umem, umem);
|
如上代码片段的处理逻辑如下:
- 创建内核
umem。
- 设置好
umem 的各个属性。
- 通过
xdp_umem_pin_pages() 将 umem 和 mmap() 分配的内存绑定起来。
- 将 AF_XDP socket 的
umem 属性指向 umem。
AF_XDP socket 绑定网卡 queue
将 AF_XDP socket 绑定网卡 queue 的系统调用是: unix.Bind(xsk.fd, &sa)。
直接看下内核源代码的 bind() 做了哪些处理吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// ${KERNEL}/net/xdp/sxk.c
static const struct proto_ops xsk_proto_ops = {
.family = PF_XDP,
// ...
.bind = xsk_bind,
// ...
};
static int xsk_bind(struct socket *sock, struct sockaddr *addr, int addr_len)
{
// ...
dev = dev_get_by_index(sock_net(sk), sxdp->sxdp_ifindex);
// ...
qid = sxdp->sxdp_queue_id;
if (flags & XDP_SHARED_UMEM) {
// ...
} else if (!xs->umem || !xsk_validate_queues(xs)) {
// ...
} else {
/* This xsk has its own umem. */
xs->pool = xp_create_and_assign_umem(xs, xs->umem);
if (!xs->pool) {
err = -ENOMEM;
goto out_unlock;
}
err = xp_assign_dev(xs->pool, dev, qid, flags);
if (err) {
xp_destroy(xs->pool);
xs->pool = NULL;
goto out_unlock;
}
}
/* FQ and CQ are now owned by the buffer pool and cleaned up with it. */
xs->fq_tmp = NULL;
xs->cq_tmp = NULL;
xs->dev = dev;
xs->zc = xs->umem->zc;
xs->queue_id = qid;
xp_add_xsk(xs->pool, xs);
return err;
}
|
xsk_bind() 的主要处理逻辑如下:
- 使用
umem 创建一个缓冲池。
- 将该缓冲池绑定到
qid 对应的 rxq 和 txq。
XDP bpf prog 与 BPF_MAP_TYPE_XSKMAP bpf map
AF_XDP socket 及其 UMEM 准备好了之后,还需要拼图的另外两块碎片:XDP bpf prog 与 BPF_MAP_TYPE_XSKMAP bpf map, 才能够使用 UMEM 接收网络包。
XDP bpf prog
该 bpf prog 主要的作用就是用于分流:判断哪些网络包要 redirect 到 UMEM,其它网络包直接 PASS。
当要将网络包 redirect 到 UMEM 时,需要调用 bpf_redirect_map() 帮助函数进行 redirect。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
/**
* long bpf_redirect_map(struct bpf_map *map, u32 key, u64 flags)
* Description
* Redirect the packet to the endpoint referenced by *map* at
* index *key*. Depending on its type, this *map* can contain
* references to net devices (for forwarding packets through other
* ports), or to CPUs (for redirecting XDP frames to another CPU;
* but this is only implemented for native XDP (with driver
* support) as of this writing).
*
* The lower two bits of *flags* are used as the return code if
* the map lookup fails. This is so that the return value can be
* one of the XDP program return codes up to **XDP_TX**, as chosen
* by the caller. The higher bits of *flags* can be set to
* BPF_F_BROADCAST or BPF_F_EXCLUDE_INGRESS as defined below.
*
* With BPF_F_BROADCAST the packet will be broadcasted to all the
* interfaces in the map, with BPF_F_EXCLUDE_INGRESS the ingress
* interface will be excluded when do broadcasting.
*
* See also **bpf_redirect**\ (), which only supports redirecting
* to an ifindex, but doesn't require a map to do so.
* Return
* **XDP_REDIRECT** on success, or the value of the two lower bits
* of the *flags* argument on error.
*/
|
高性能场景下使用 bpf_redirect_map() 的参数如下:
map 指向 BPF_MAP_TYPE_XSKMAP bpf map。key 使用 xdp->rxq->queue_index(xdp 指的是 XDP bpf prog 的上下文,类型 struct xdp_buff *)。flags 为 0.
也就是说,将当前网络包 redirect 到当前网卡 queue index 对应的 AF_XDP socket 的 UMEM 中。
BPF_MAP_TYPE_XSKMAP bpf map
不过,要成功将网络包 redirect 到 UMEM,还需要 BPF_MAP_TYPE_XSKMAP bpf map 中存有映射关系:queue index -> AF_XDP socket fd。
所以,在用户态应用程序中,在 NewSocket() 之后,还需要 map.Update(queueID, xsk.Fd()) 将它们的映射关系保存到 BPF_MAP_TYPE_XSKMAP bpf map 中。
否则,如果 BPF_MAP_TYPE_XSKMAP bpf map 中没有对应的 entry,XDP bpf prog 进行 redirect 最终会失败。
看下 map.Update() 保存的是什么(不是 AF_XDP socket fd,而是 AF_XDP socket):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
const struct bpf_map_ops xsk_map_ops = {
// ...
.map_update_elem = xsk_map_update_elem,
// ...
};
static int xsk_map_update_elem(struct bpf_map *map, void *key, void *value,
u64 map_flags)
{
struct xsk_map *m = container_of(map, struct xsk_map, map);
struct xdp_sock __rcu **map_entry;
struct xdp_sock *xs, *old_xs;
u32 i = *(u32 *)key, fd = *(u32 *)value;
// ...
sock = sockfd_lookup(fd, &err);
// ...
xs = (struct xdp_sock *)sock->sk;
map_entry = &m->xsk_map[i];
node = xsk_map_node_alloc(m, map_entry);
// ...
xsk_map_sock_add(xs, node);
rcu_assign_pointer(*map_entry, xs);
// ...
return 0;
out:
// ...
return err;
}
|
如上代码片段的主要处理逻辑如下:
- 查询 fd 对应的 AF_XDP socket。
- 将查询到的 AF_XDP socket 保存到 key 对应的 entry 里。
XDP redirect
进行 redirect 的前置条件皆已准备好,接下来直接看看一个网络包是怎么从 XDP 到 AF_XDP 的。
关于 XDP redirect,请学习 eBPF Talk: 揭秘 XDP 转发网络包。
真实的 redirect 处理分两步走:
bpf_redirect_map()。- 内核对 XDP_REDIRECT 的处理。
bpf_redirect_map()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
// ${KERNEL}/net/core/filter.c
BPF_CALL_3(bpf_xdp_redirect_map, struct bpf_map *, map, u32, ifindex,
u64, flags)
{
return map->ops->map_redirect(map, ifindex, flags);
}
// ${KERNEL}/net/xdp/xskmap.c
const struct bpf_map_ops xsk_map_ops = {
// ...
.map_redirect = xsk_map_redirect,
};
static int xsk_map_redirect(struct bpf_map *map, u32 ifindex, u64 flags)
{
return __bpf_xdp_redirect_map(map, ifindex, flags, 0,
__xsk_map_lookup_elem);
}
// ${KERNEL}/include/linux/filter.h
static __always_inline int __bpf_xdp_redirect_map(struct bpf_map *map, u32 ifindex,
u64 flags, const u64 flag_mask,
void *lookup_elem(struct bpf_map *map, u32 key))
{
struct bpf_redirect_info *ri = this_cpu_ptr(&bpf_redirect_info);
const u64 action_mask = XDP_ABORTED | XDP_DROP | XDP_PASS | XDP_TX;
/* Lower bits of the flags are used as return code on lookup failure */
if (unlikely(flags & ~(action_mask | flag_mask)))
return XDP_ABORTED;
ri->tgt_value = lookup_elem(map, ifindex);
// ...
ri->tgt_index = ifindex;
ri->map_id = map->id;
ri->map_type = map->map_type;
// ...
return XDP_REDIRECT;
}
// ${KERNEL}/net/xdp/xskmap.c
/* Elements are kept alive by RCU; either by rcu_read_lock() (from syscall) or
* by local_bh_disable() (from XDP calls inside NAPI). The
* rcu_read_lock_bh_held() below makes lockdep accept both.
*/
static void *__xsk_map_lookup_elem(struct bpf_map *map, u32 key)
{
struct xsk_map *m = container_of(map, struct xsk_map, map);
if (key >= map->max_entries)
return NULL;
return rcu_dereference_check(m->xsk_map[key], rcu_read_lock_bh_held());
}
|
如上代码片段的处理逻辑如下:
- 从 BPF_MAP_TYPE_XSKMAP bpf map 中使用指定 key (即
xdp->rxq->queue_index)查询出对应的值(即 AF_XDP socket)。
- 将查找到的 AF_XDP socket 保存到
this_cpu_ptr(&bpf_redirect_info),后面步骤会从这里取出 AF_XDP socket。
内核对 XDP_REDIRECT 的处理
参考 eBPF Talk: 揭秘 XDP 转发网络包。
1
2
3
4
5
6
7
|
xdp_do_generic_redirect_map() // ${KERNEL}/kernel/core/filter.c
|-->xsk_generic_rcv() // ${KERNEL}/net/xdp/xsk.c
|-->__xsk_rcv()
| |-->xsk_xdp = xsk_buff_alloc(xs->pool);
| |-->xsk_copy_xdp(xsk_xdp, xdp, len);
| |-->__xsk_rcv_zc(xs, xsk_xdp, len);
|-->xsk_flush()
|
如上代码片段的主要处理逻辑如下:
- 从 UMEM 缓冲池里分配一块内存。
- 将网络包复制到该内存中。
xsk_flush() release 一下 fill queue。
总结
对着 AF_XDP 一番研究,仅仅是研究了高性能 AF_XDP 的冰山一角。
- 复杂的用户态应用程序处理。
- 网卡独占的 XDP bpf prog 和 BPF_MAP_TYPE_XSKMAP bpf map。
仅仅是如上两个步骤,还不足以成为高性能 AF_XDP,还需要:
- 使用类 DPDK 的 PMD 模式去设计用户态应用程序。
- 使用
ethtool ntuple 在网卡里配置 RSS 进行网络包分发。
其中 PMD 模式就涉及 CPU 亲和性和 NUMA 配置,为了内核处理逻辑、用户态应用程序处理逻辑都在同一个 CPU 上处理同一个网络包,使得网络包所在内存的 CPU 亲和性最大化(最大程度降低 CPU cache miss)。
合适的 ethtool ntuple 配置,会按需将网络包分发到对应的网卡 queue 中;比如,同一个源地址的网络包只会分发到同一个 queue 中。
除了高性能 AF_XDP 外,AF_XDP 本身的实现机制也值得探索一番;毕竟这是一个使用 mmap() 实现内核、用户程序进行高性能编程的工业级案例。

