本系列是 x86 架构平台上 trampoline 的实现,从原理和实现上进行了详细的介绍。
小司机们,是时候学习真正的 eBPF 挖掘机技术了:指令插桩,以及指令 live patch。
TL;DR 在 x86 架构平台上的指令插桩&补丁的步骤如下:
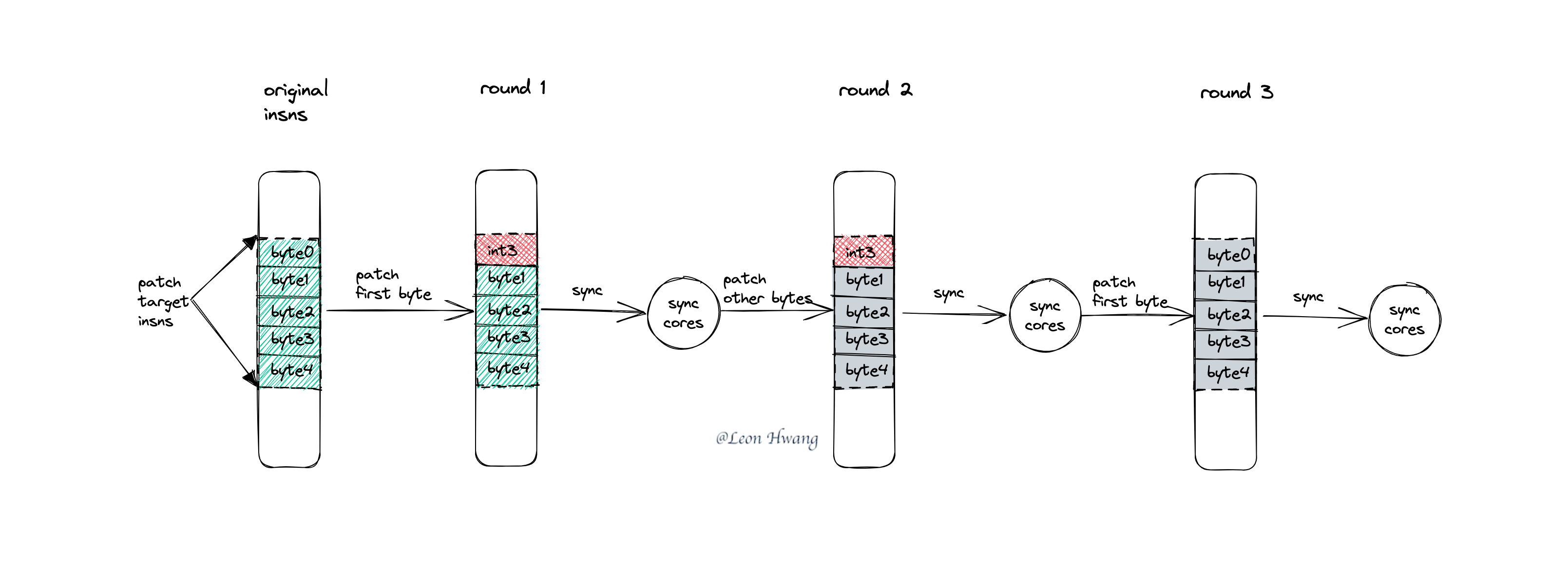
- 在需要的地方预留 PATCH_SIZE 大小的 nop 指令。(插桩,后面的步骤皆为补丁过程)
- 将第一个字节替换成 int3 指令。
- 同步所有 CPU(sync cores)。
- 除了第一个字节,将其它字节替换为目标字节。
- 同步所有 CPU(sync cores)。
- 将第一个字节替换为目标字节。
- 同步所有 CPU(sync cores)。
作为 eBPF 开发老司机,在 x86 架构平台面前仅是小司机一枚,在此诚惶诚恐地抛砖引玉,开始学习 eBPF 依赖的一些 x86 技术。
JIT on x86
x86 支持将 eBPF 汇编即时编译成机器指令:
1
2
3
4
5
6
|
// ${KERNEL}/arch/x86/net/bpf_jit_comp.c
struct bpf_prog *bpf_int_jit_compile(struct bpf_prog *prog)
{
// ...
}
|
bpf_int_jit_compile() 便是 x86 JIT 的入口函数。这也是学习 eBPF on x86 的入口。
在学习 tailcall and bpf2bpf on x86 的时候,便已了解到 x86 上 tailcall 替换 JMP 指令目标地址的过程。问:x86 上是怎么替换 JMP 指令目标地址的?
插桩 on x86
eBPF 只会依赖 x86 架构平台已有的能力,特别是指令补丁的能力;基于指令补丁能力,eBPF 发展出了 staic tailcall、freplace 等特性。
所以,只要掌握了 x86 指令补丁技术,就能轻松地理解 eBPF 的 staic tailcall、freplace 等特性的实现。
x86 指令补丁技术并不神秘,简单而言,就是预留需要补丁的指令位置(用 nop 指令填充)、然后在预留的位置上替换指令。
因而,在学习 bpf_jit_comp.c 源代码的时候,会看到不少 memcpy(prog, x86_nops[5], X86_PATCH_SIZE); 代码;这就是插桩的真面目了。
X86_PATCH_SIZE 是 5,指 5 个字节,因为指令 CALL/JMP ${target address} 的字节数为 5 (CALL/JMP 指令编号占 1 个字节,${target address} 目标地址占 4 个字节)。
补丁 on x86
eBPF 本身并没有打补丁的能力,使用的都是 x86 提供的指令补丁的能力。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
// ${KERNEL}/arch/x86/net/bpf_jit_comp.c
static int __bpf_arch_text_poke(void *ip, enum bpf_text_poke_type t,
void *old_addr, void *new_addr)
{
const u8 *nop_insn = x86_nops[5];
u8 old_insn[X86_PATCH_SIZE];
u8 new_insn[X86_PATCH_SIZE];
u8 *prog;
int ret;
memcpy(old_insn, nop_insn, X86_PATCH_SIZE);
if (old_addr) {
prog = old_insn;
ret = t == BPF_MOD_CALL ?
emit_call(&prog, old_addr, ip) :
emit_jump(&prog, old_addr, ip);
if (ret)
return ret;
}
memcpy(new_insn, nop_insn, X86_PATCH_SIZE);
if (new_addr) {
prog = new_insn;
ret = t == BPF_MOD_CALL ?
emit_call(&prog, new_addr, ip) :
emit_jump(&prog, new_addr, ip);
if (ret)
return ret;
}
ret = -EBUSY;
mutex_lock(&text_mutex);
if (memcmp(ip, old_insn, X86_PATCH_SIZE))
goto out;
ret = 1;
if (memcmp(ip, new_insn, X86_PATCH_SIZE)) {
text_poke_bp(ip, new_insn, X86_PATCH_SIZE, NULL);
ret = 0;
}
out:
mutex_unlock(&text_mutex);
return ret;
}
int bpf_arch_text_poke(void *ip, enum bpf_text_poke_type t,
void *old_addr, void *new_addr)
{
if (!is_kernel_text((long)ip) &&
!is_bpf_text_address((long)ip))
/* BPF poking in modules is not supported */
return -EINVAL;
/*
* See emit_prologue(), for IBT builds the trampoline hook is preceded
* with an ENDBR instruction.
*/
if (is_endbr(*(u32 *)ip))
ip += ENDBR_INSN_SIZE;
return __bpf_arch_text_poke(ip, t, old_addr, new_addr);
}
|
__bpf_arch_text_poke() 主要处理逻辑如下:
- 利用原有的信息,判断在进行本次 poke 时原有的指令是否有变更了,如果有变更则跳过本次 poke。
- 根据 poke 类型生成新的指令(
CALL/JMP ${target address})。
- 调用
text_poke_bp() 进行指令 live patch。
简单理解,便是将插桩的 nop 指令 live patch 为 CALL/JMP ${target address} 指令。
可以看到,最终调用 text_poke_bp() 函数对指令进行 live patch。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
|
// ${KERNEL}/arch/x86/kernel/alternative.c
/**
* text_poke_bp() -- update instructions on live kernel on SMP
* @addr: address to patch
* @opcode: opcode of new instruction
* @len: length to copy
* @emulate: instruction to be emulated
*
* Update a single instruction with the vector in the stack, avoiding
* dynamically allocated memory. This function should be used when it is
* not possible to allocate memory.
*/
void __ref text_poke_bp(void *addr, const void *opcode, size_t len, const void *emulate)
{
struct text_poke_loc tp;
if (unlikely(system_state == SYSTEM_BOOTING)) {
text_poke_early(addr, opcode, len);
return;
}
text_poke_loc_init(&tp, addr, opcode, len, emulate);
text_poke_bp_batch(&tp, 1);
}
/**
* text_poke_bp_batch() -- update instructions on live kernel on SMP
* @tp: vector of instructions to patch
* @nr_entries: number of entries in the vector
*
* Modify multi-byte instruction by using int3 breakpoint on SMP.
* We completely avoid stop_machine() here, and achieve the
* synchronization using int3 breakpoint.
*
* The way it is done:
* - For each entry in the vector:
* - add a int3 trap to the address that will be patched
* - sync cores
* - For each entry in the vector:
* - update all but the first byte of the patched range
* - sync cores
* - For each entry in the vector:
* - replace the first byte (int3) by the first byte of
* replacing opcode
* - sync cores
*/
static void text_poke_bp_batch(struct text_poke_loc *tp, unsigned int nr_entries)
{
unsigned char int3 = INT3_INSN_OPCODE;
unsigned int i;
int do_sync;
lockdep_assert_held(&text_mutex);
bp_desc.vec = tp;
bp_desc.nr_entries = nr_entries;
/*
* Corresponds to the implicit memory barrier in try_get_desc() to
* ensure reading a non-zero refcount provides up to date bp_desc data.
*/
atomic_set_release(&bp_desc.refs, 1);
/*
* Corresponding read barrier in int3 notifier for making sure the
* nr_entries and handler are correctly ordered wrt. patching.
*/
smp_wmb();
/*
* First step: add a int3 trap to the address that will be patched.
*/
for (i = 0; i < nr_entries; i++) {
tp[i].old = *(u8 *)text_poke_addr(&tp[i]);
text_poke(text_poke_addr(&tp[i]), &int3, INT3_INSN_SIZE);
}
text_poke_sync();
/*
* Second step: update all but the first byte of the patched range.
*/
for (do_sync = 0, i = 0; i < nr_entries; i++) {
u8 old[POKE_MAX_OPCODE_SIZE] = { tp[i].old, };
int len = tp[i].len;
if (len - INT3_INSN_SIZE > 0) {
memcpy(old + INT3_INSN_SIZE,
text_poke_addr(&tp[i]) + INT3_INSN_SIZE,
len - INT3_INSN_SIZE);
text_poke(text_poke_addr(&tp[i]) + INT3_INSN_SIZE,
(const char *)tp[i].text + INT3_INSN_SIZE,
len - INT3_INSN_SIZE);
do_sync++;
}
// ...
// perf event
}
if (do_sync) {
/*
* According to Intel, this core syncing is very likely
* not necessary and we'd be safe even without it. But
* better safe than sorry (plus there's not only Intel).
*/
text_poke_sync();
}
/*
* Third step: replace the first byte (int3) by the first byte of
* replacing opcode.
*/
for (do_sync = 0, i = 0; i < nr_entries; i++) {
if (tp[i].text[0] == INT3_INSN_OPCODE)
continue;
text_poke(text_poke_addr(&tp[i]), tp[i].text, INT3_INSN_SIZE);
do_sync++;
}
if (do_sync)
text_poke_sync();
/*
* Remove and wait for refs to be zero.
*/
if (!atomic_dec_and_test(&bp_desc.refs))
atomic_cond_read_acquire(&bp_desc.refs, !VAL);
}
|
用图片展示该过程:
总结
学习了 x86 指令插桩、指令 live patch 技术,可以更好地驾驶 eBPF 挖掘机了。
tailcall、bpf2bpf on x86 不再神秘。

