最近学习了网络包在线分类算法 TupleMerge,惊讶于其高效的查询和更新效率,比基于 bitmap 的算法更加节省内存、查询效率更高。本文将介绍 TupleMerge 算法的原理和实现,以及如何在 XDP 中使用 TupleMerge 算法实现 ACL。
复习之前实现的 XDP ACL:
TupleMerge 算法
TupleMerge 算法来自如下论文:
不过,该论文晦涩难懂,还是推荐阅读下面的 (还没合入上游) kernel patch:
参考 kernel patch,TupleMerge 算法的原理如下:
1. 分表
按照一定规则,将 ACL rule 分成多个表,每个表有一个不重复的 ID,和该表对应的 rule 描述。
比如 kernel patch 里的分表规则:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
static int tm_table_compatible(const struct bpf_wildcard *wcard,
const struct tm_table *table,
const struct wildcard_key *key)
{
u32 off = 0;
u32 size, i;
u32 prefix;
for (i = 0; i < wcard->desc->n_rules; i++) {
size = wcard->desc->rule_desc[i].size;
switch (wcard->desc->rule_desc[i].type) {
case BPF_WILDCARD_RULE_PREFIX:
prefix = *(u32 *)(key->data + off + size);
/* table only is compatible if its prefix is less than or equal rule prefix */
if (table->mask->prefix[i] > prefix)
return 0;
off += size + sizeof(u32);
break;
case BPF_WILDCARD_RULE_RANGE:
/* ignore this case, table is always compatible */
off += 2 * size;
break;
case BPF_WILDCARD_RULE_MATCH:
/* ignore this case, table is always compatible */
off += size;
break;
}
}
return 1;
}
|
即,只适配类似 CIDR 的 prefix 规则项,其他的规则项忽略。
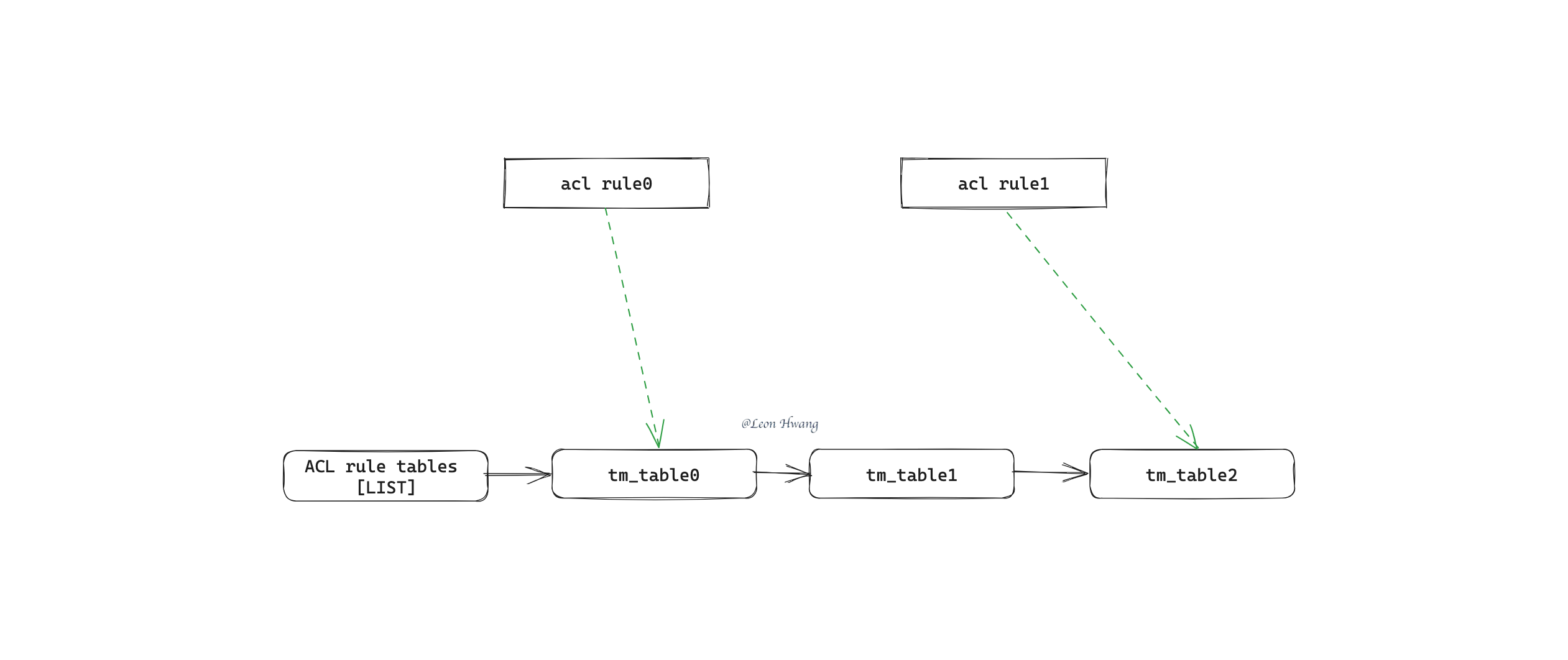
然后,就所有 rule 依赖的表保存到一个链表里。
2. 哈希
为了高效查询,哈希是必选项。不过,选择哈希,必定需要处理哈希冲突。TupleMerge 算法的处理方式是,将哈希冲突的 rule 保存到一个链表里。
不过,使用哪些字段进行哈希呢?
kernel patch 里的哈希规则如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
static u32 tm_hash_rule(const struct wildcard_desc *desc,
const struct tm_table *table,
const struct wildcard_key *key)
{
u8 buf[BPF_WILDCARD_MAX_TOTAL_RULE_SIZE];
const void *data = key->data;
u32 type, size, i;
u32 n = 0;
for (i = 0; i < desc->n_rules; i++) {
type = desc->rule_desc[i].type;
size = desc->rule_desc[i].size;
if (type == BPF_WILDCARD_RULE_RANGE ||
(type == BPF_WILDCARD_RULE_PREFIX && !table->mask->prefix[i]))
goto ignore;
if (likely(type == BPF_WILDCARD_RULE_PREFIX))
__tm_copy_masked_rule(buf+n, data, size, table->mask->prefix[i]);
else if (type == BPF_WILDCARD_RULE_MATCH)
memcpy(buf+n, data, size);
n += size;
ignore:
switch (desc->rule_desc[i].type) {
case BPF_WILDCARD_RULE_PREFIX:
data += size + sizeof(u32);
break;
case BPF_WILDCARD_RULE_RANGE:
data += 2 * size;
break;
case BPF_WILDCARD_RULE_MATCH:
data += size;
break;
}
}
return jhash(buf, n, table->id);
}
|
使用非 RANGE 类型的规则项,且对 PREFIX 类型的规则项进行 mask 处理,然后把分表 ID 当作随机因子、使用 jhash 算法进行哈希。
3. 分组
进行哈希后,简单计算后便可得到分组数组中的某一个分组,然后将 rule 保存到该分组的链表里;当然,在保存时,可根据优先级保存到链表的某个位置。
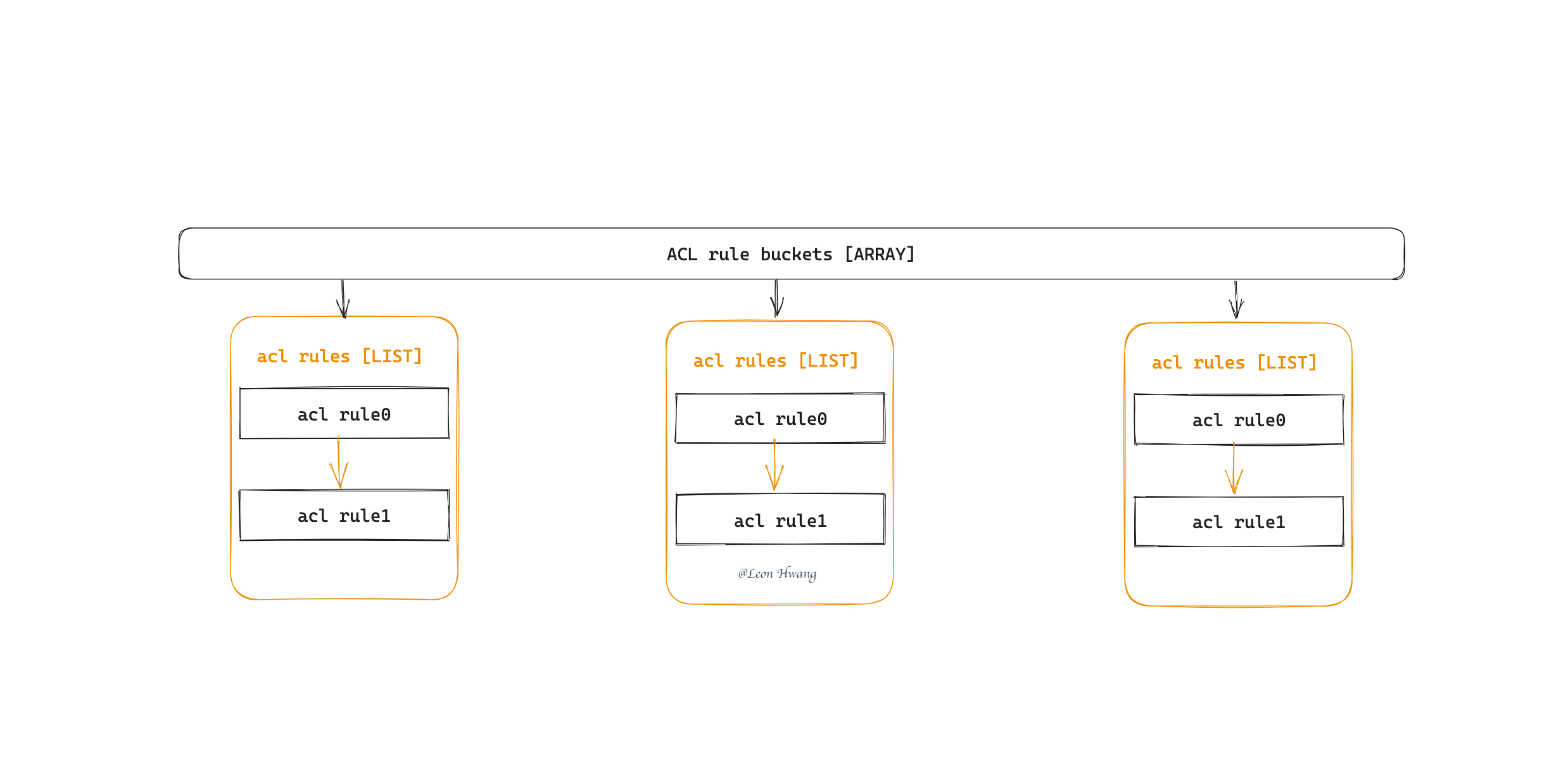
4. 匹配
匹配步骤如下:
- 遍历分表。
- 计算哈希。
- 查询分组。
- 遍历分组里的所有规则。
- 匹配规则。
kernel patch 里的匹配规则如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
static u32 tm_hash(const struct wildcard_desc *desc,
const struct tm_table *table,
const struct wildcard_key *key)
{
u8 buf[BPF_WILDCARD_MAX_TOTAL_RULE_SIZE];
const void *data = key->data;
u32 type, size, i;
u32 n = 0;
for (i = 0; i < desc->n_rules; i++) {
type = desc->rule_desc[i].type;
size = desc->rule_desc[i].size;
if (type == BPF_WILDCARD_RULE_RANGE ||
(type == BPF_WILDCARD_RULE_PREFIX && !table->mask->prefix[i]))
goto ignore;
if (likely(type == BPF_WILDCARD_RULE_PREFIX))
__tm_copy_masked_elem(buf+n, data, size, table->mask->prefix[i]);
else if (type == BPF_WILDCARD_RULE_MATCH)
memcpy(buf+n, data, size);
n += size;
ignore:
data += size;
}
return jhash(buf, n, table->id);
}
static void *tm_match(const struct bpf_wildcard *wcard,
const struct wildcard_key *key)
{
struct tm_bucket *bucket;
struct tm_table *table;
struct wcard_elem *l;
u32 hash;
list_for_each_entry_rcu(table, &wcard->tables_list_head, list) { // 遍历分表
hash = tm_hash(wcard->desc, table, key); // 计算哈希
bucket = &wcard->buckets[hash & (wcard->n_buckets - 1)]; // 查询分组
hlist_for_each_entry_rcu(l, &bucket->head, node) { // 遍历分组里的所有规则
if (l->hash != hash)
continue;
if (l->table_id != table->id)
continue;
if (__match(wcard->desc, (void *)l->key, key)) // 匹配规则
return l;
}
}
return NULL;
}
|
已习得 TupleMerge 算法的精髓,那么有没有办法使用纯 bpf 来实现呢?
pure-bpf TupleMerge demo
既已明白 TupleMerge 算法是怎么回事,那么就使用纯 bpf 来实现一个匹配 IPv4 五元组规则的 demo 吧。
规则描述如下:
1
2
3
4
5
6
7
8
9
|
{
"saddr": "10.11.12.0/24",
"daddr": "192.168.1.0/24",
"proto": "tcp",
"dport": "22",
"sport": "1024-65535",
"action": "allow",
"priority": 2
}
|
对应到 XDP 里,规则描述如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
struct acl_rule {
__u32 table_id;
__u32 hash;
__u8 protocol;
__be32 saddr;
__be32 smask;
__be32 daddr;
__be32 dmask;
__be16 sport_start;
__be16 sport_end;
__be16 dport_start;
__be16 dport_end;
__u8 action;
__u16 _pad;
} __attribute__((packed));
|
不过,不同于 kernel patch,eBPF 里要到 6.2 版本才支持链表。所以,这里使用数组来保存分表和规则。也就是,分表保存到一个 ARRAY bpf map 里,规则保存到一些 ARRAY bpf map 里;而分组则保存到一个 ARRAY_OF_MAPS bpf map 里。
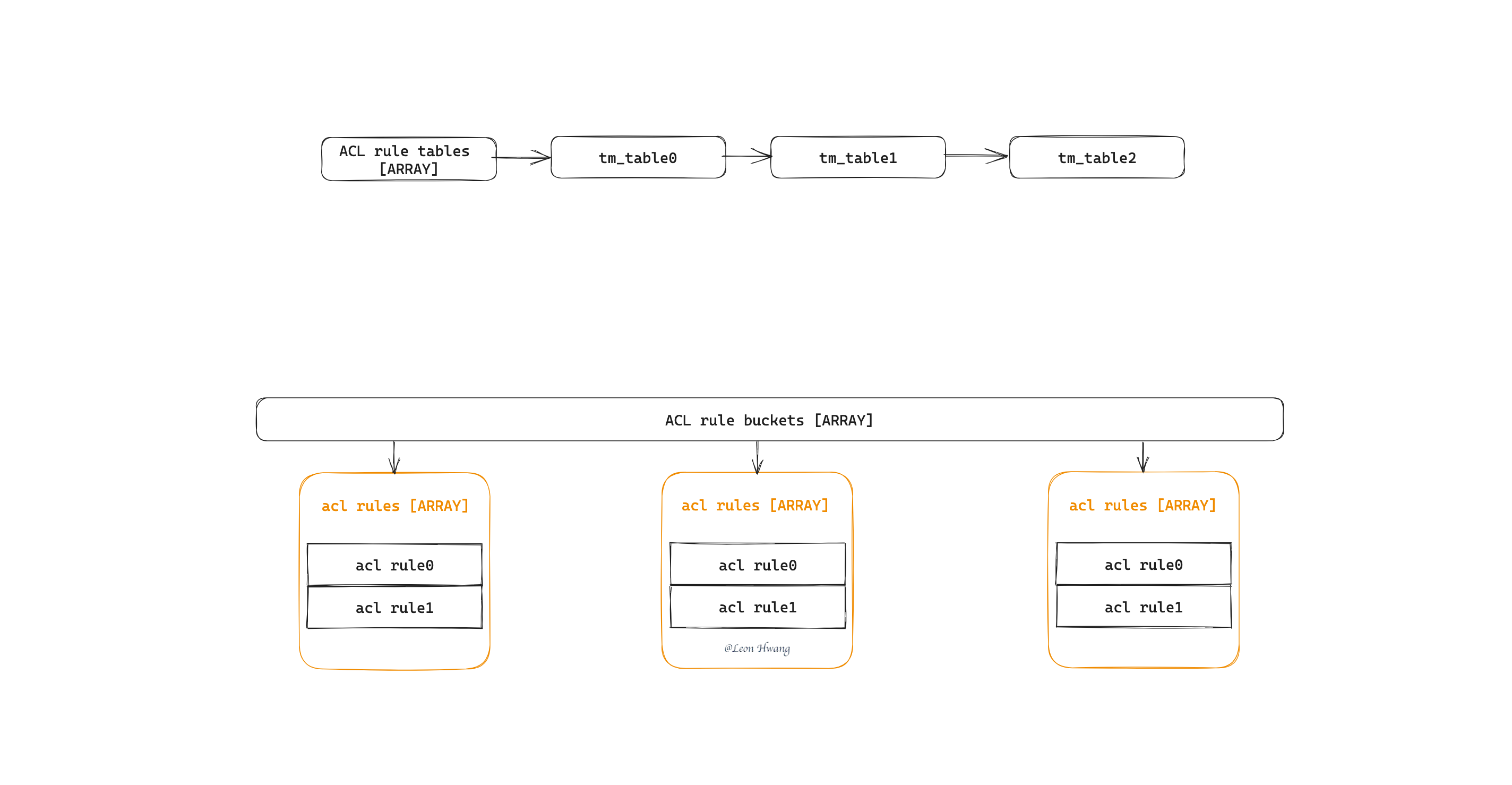
因此,需要用户态空间的 Go 代码来管理这些 bpf map,并且在处理 rule 时使用同一套哈希算法。
分表处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func (t *aclTables) findCompatibleTable(smaskBits, dmaskBits int) *aclTable {
for _, table := range *t {
// xbits <= ybits means ybits is a subset of xbits
if table.smaskBits <= smaskBits && table.dmaskBits <= dmaskBits {
return table
}
}
tblID := randID()
for t.isTableIDUsed(tblID) {
tblID = randID()
}
tbl := &aclTable{
ID: tblID,
smaskBits: smaskBits,
dmaskBits: dmaskBits,
}
*t = append(*t, tbl)
return tbl
}
|
只需要看 saddr 和 daddr 是否合适即可。
哈希:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func (r *rule) doHash() {
var hashKey struct {
saddr [4]byte
daddr [4]byte
protocol uint8
}
hashKey.saddr = r.saddr
hashKey.daddr = r.daddr
hashKey.protocol = r.protocol
b := (*[9]byte)(unsafe.Pointer(&hashKey))[:]
r.hash = jhash(b, r.tableID)
}
|
此处的 r.saddr 和 r.daddr 是已经 mask 处理过的,所以直接提供给 jhash 即可。
而 jhash 则是参考 kernel 的实现,直接移植过来的。
分组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func (a *xdpAcl) saveRulesToMap(m *ebpf.Map, save func([]*rule) (*ebpf.Map, error)) error {
maxEntries := m.MaxEntries()
if !isPowOf2(maxEntries) { // 必须是 2 的幂
return fmt.Errorf("map max entries must be power of 2")
}
var index []uint32
arr := make([][]*rule, maxEntries)
for _, r := range a.rules {
idx := r.hash & (maxEntries - 1) // 计算所在分组的索引
arr[idx] = append(arr[idx], r) // 保存到分组里
index = append(index, idx)
}
for _, idx := range index {
innerMap, err := save(arr[idx]) // 将规则保存到分组里
if err != nil {
return fmt.Errorf("failed to save rules: %w", err)
}
defer innerMap.Close()
if err := m.Update(idx, innerMap, ebpf.UpdateAny); err != nil { // 将分组保存到 ARRAY_OF_MAPS 里
return fmt.Errorf("failed to update acl buckets map: %w", err)
}
}
return nil
}
|
匹配:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
struct rule_matching {
struct packet pkt;
__u32 table_id;
__u32 hash;
__u8 matched;
__u8 action;
__u8 pad;
} __attribute__((aligned(4)));
static __always_inline bool __match_rule(
struct acl_rule *rule, struct packet *pkt)
{
return ((rule->protocol == pkt->protocol) &&
(rule->saddr == (pkt->saddr & rule->smask)) &&
(rule->daddr == (pkt->daddr & rule->dmask)) &&
(pkt->protocol == IPPROTO_ICMP || // tcp/udp
(((rule->sport_start <= pkt->sport) &&
(pkt->sport <= rule->sport_end)) &&
((rule->dport_start <= pkt->dport) &&
(pkt->dport <= rule->dport_end)))));
}
static int __iterate_rules(struct bpf_map *map, const __u32 *key,
struct acl_rule *value, struct rule_matching *match)
{
if (match->table_id != value->table_id)
return 0;
if (match->hash != value->hash)
return 0;
if (__match_rule(value, &match->pkt)) { // 匹配规则
match->matched = 1;
match->action = value->action;
return 1;
}
return 0;
}
static int __iterate_tables(struct bpf_map *map, const __u32 *key,
struct acl_rule_table *value, struct rule_matching *match)
{
struct acl_rule_hash_key hash_key = {
.saddr = match->pkt.saddr & value->smask,
.daddr = match->pkt.daddr & value->dmask,
.protocol = match->pkt.protocol,
};
match->table_id = value->id;
match->hash = jhash(&hash_key, 9, value->id); // 计算哈希值
__u32 index = match->hash & (RULE_BUCKETS_NUM - 1); // 计算所在分组的索引
void *inner_map = bpf_map_lookup_elem(&acl_rule_buckets, &index); // 从 ARRAY_OF_MAPS 里取出分组对应的 inner bpf map
if (!inner_map)
return 0;
bpf_for_each_map_elem(inner_map, __iterate_rules, match, 0); // 遍历分组里的所有规则
return match->matched ? 1 : 0;
}
static __always_inline int match_acl_rules(struct xdp_md *ctx)
{
struct rule_matching match = { 0 };
// ...
match.pkt.saddr = iph->saddr;
match.pkt.daddr = iph->daddr;
match.pkt.protocol = iph->protocol;
bpf_for_each_map_elem(&acl_tables, __iterate_tables, &match, 0); // 遍历所有的分表
return match.matched ? match.action : XDP_PASS;
}
|
其中,使用的 bpf_for_each_map_elem() 是 5.15 kernel 新增的 BPF helper,用于遍历 map。
最终,通过 Go 和 eBPF 的巧妙组合,便可实现一个简化版的 TupleMerge 算法。
小结
本文介绍了 TupleMerge 算法的原理,以及如何使用 Go 和 eBPF 实现一个简化版的 TupleMerge 算法。

