在 eBPF Talk: trace tailcall 程序?NO! 里,我们知道 tailcall 程序是不能直接使用 fentry/fexit 进行 trace 的。
如果通过内核模块,使用比较 hack 的方式,能否 trace tailcall 程序呢?
TL;DR 能对静态 tailcall 进行 trace,还不能对动态 tailcall 进行 trace。
设计内核模块
经过好几次试验,最终设计出了一个可以对静态 tailcall 进行 trace 的内核模块。
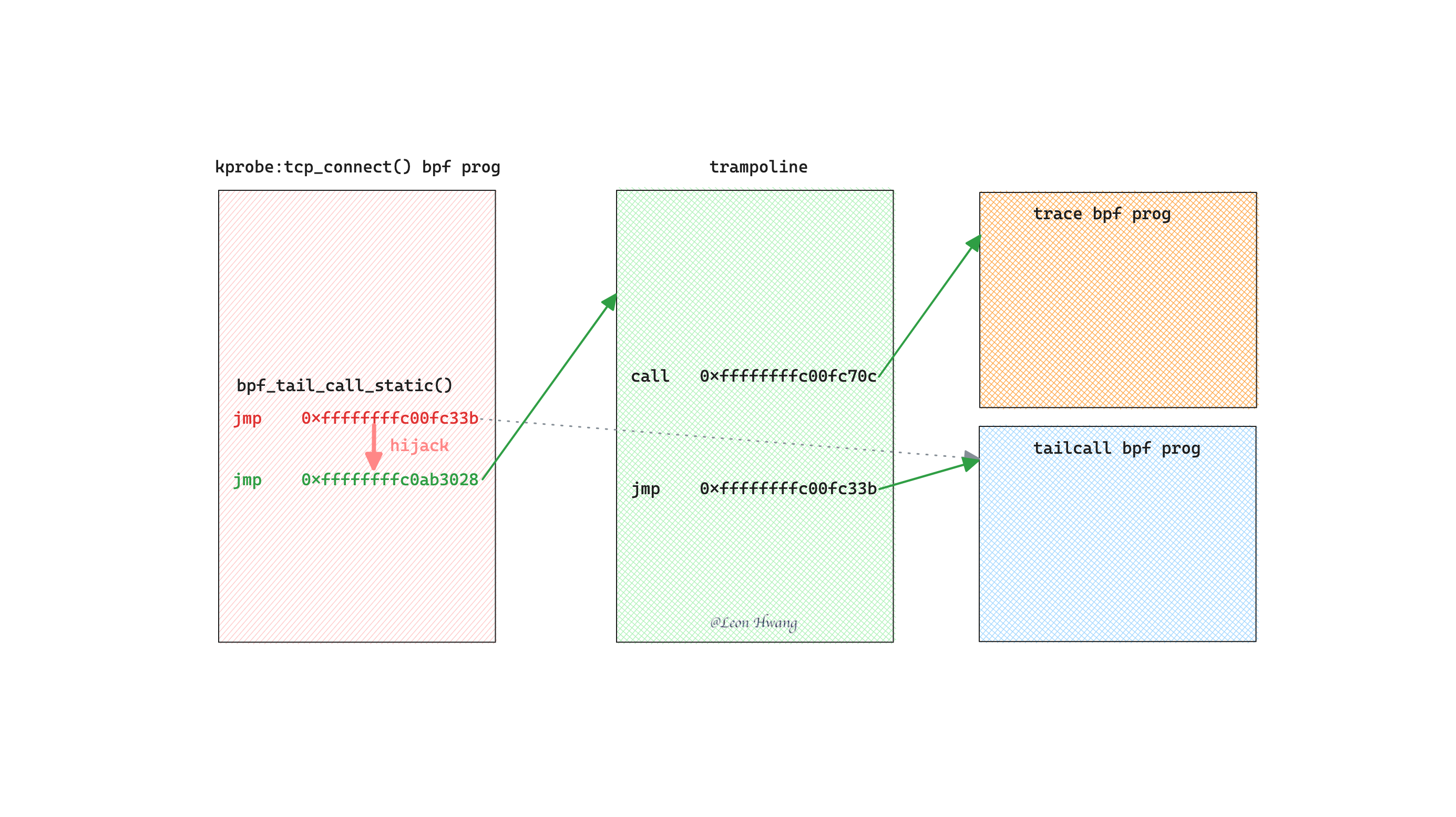
如上图所示,该内核模块的设计思路是:
- 劫持
bpf_tail_call_static() 所使用的 jmp 指令。
- 劫持后的
jmp 指令跳转到内核模块准备好了的 trampoline。
- 在 trampoline 里,使用
call 指令调用用来 trace 的 bpf prog。
- 最后,使用
jmp 指令跳转回 bpf_tail_call_static() 的目标 bpf prog。
最终效果如下:
1
2
3
4
5
6
7
8
|
# ./bpf-tailcall-tracer
2023/08/26 15:12:07 Attached kprobe(tcp_connect)
2023/08/26 15:12:07 Attached kprobe(inet_csk_complete_hashdance)
2023/08/26 15:12:07 Listening events...
2023/08/26 15:26:27 new tcp connection: 192.168.64.11:59106 -> 142.251.12.113:80 (fentry on index: 2)
2023/08/26 15:26:27 new tcp connection: 192.168.64.11:59106 -> 142.251.12.113:80 (kprobe)
2023/08/26 15:26:31 new tcp connection: 192.168.64.11:22 -> 192.168.64.1:62039 (fentry on index: 3)
2023/08/26 15:26:31 new tcp connection: 192.168.64.11:22 -> 192.168.64.1:62039 (kprobe)
|
实现静态 tailcall 的 tracer
今年 2 月的时候,和一位大佬讨论过如何 trace tailcall 程序。
而后,到 7 月的时候,确认无法直接使用 fentry/fexit trace tailcall 程序。
接着,历时 1 个多月,使用内核模块这样 hack 的方式,从想法到实验,终于能够对静态 tailcall 进行 trace 了。
实现细节 1:设计 trampoline
经历了 3 个想法后,最终使用 trampoline 的方式实现了对静态 tailcall 的 trace。
该 trampoline 比较简单,如下:
1
2
3
4
5
6
7
8
9
10
11
|
/*
* trampoline image:
* 1: push %rax // tail_call_cnt
* 2: push %rdi // first arg, aka ctx
* 3: mov %esi, ${index} // second arg, array index
* 4: call ${fentry_tailcall} // call fentry bpf prog
* 5: pop %rdi // pop stack
* 6: pop %rax // pop stack
* 7: jmp ${tgt_prog} // jump to target prog
* 8: nop // extra space
*/
|
为了生成这段汇编,直接从 ${KERNEL}/arch/x86/net/bpf_jit_comp.c 里抄了不少代码;也从 ${KERNEL}/kernel/bpf/trampoline.c 里抄了管理 trampoline image 的代码。
最终,能够生成如下 trampoline image:
1
2
3
4
5
6
7
8
|
0xffffffffc0ab3000: push %rax
0xffffffffc0ab3001: push %rdi
0xffffffffc0ab3002: mov $0x0,%esi
0xffffffffc0ab3007: call 0xffffffffc00fb598
0xffffffffc0ab300c: pop %rdi
0xffffffffc0ab300d: pop %rax
0xffffffffc0ab300e: jmp 0xffffffffc00fb1b3
0xffffffffc0ab3013: nop
|
实现细节 2:多个 trampoline
如上的 trampoline 存在一个问题:它使用的数组索引是固定的,而不是动态的。
所以,为了支持多个 tailcall bpf prog,需要多个 trampoline;每个静态 tailcall 对应一个 trampoline。
简单起见,最多支持 PAGE_SIZE / 20 个 trampoline;这是因为每个 trampoline 的大小是 20 字节。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#define TRAMP_IMAGE_SIZE 20
#define TRAMP_IMAGE_CAP (PAGE_SIZE / TRAMP_IMAGE_SIZE)
static bool __tramp_constructed[TRAMP_IMAGE_CAP] = {};
static void *bpf_tailcall_tramp_image = NULL;
static int
__construct_tramp_images(struct bpf_array *array, struct bpf_prog *fentry_prog)
{
struct bpf_prog *bp;
u8 *prog;
int ret;
u32 i;
for (i = 0; i<array->map.max_entries && i<TRAMP_IMAGE_CAP; i++) {
if (__has_contructed(i))
continue;
bp = (struct bpf_prog *) array->ptrs[i];
if (!bp)
continue;
prog = __get_tramp_image(i);
ret = __construct_tramp_image(prog, bp, fentry_prog, i);
if (unlikely(ret)) {
pr_err("[X] __construct_tramp_image failed: %d\n", ret);
return ret;
}
__mark_constructed(i);
}
/* int3 */
__fill_hole(prog, PAGE_SIZE - (TRAMP_IMAGE_SIZE * i));
return 0;
}
|
实现细节 3:劫持 jmp 指令
参考 eBPF Talk: 更新 tailcall PROG_ARRAY bpf map 里的 prog_array_map_poke_run(),劫持 jmp 指令的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
static int
__bpf_poke_progs(struct bpf_array *array, bool is_hack)
{
struct bpf_array_aux *aux = array->aux;
struct prog_poke_elem *elem;
list_for_each_entry(elem, &aux->poke_progs, list) {
// ...
for (i = 0; i < elem->aux->size_poke_tab; i++) {
poke = &elem->aux->poke_tab[i];
if (poke->tail_call.map != map)
continue;
key = poke->tail_call.key;
// ...
prog = (struct bpf_prog *) array->ptrs[key];
p = (u8 *) prog->bpf_func + X86_TAIL_CALL_OFFSET;
pp = __get_tramp_image(key);
if (is_hack) {
from = p;
to = pp;
} else {
from = pp;
to = p;
}
ret = bpf_arch_text_poke_fn(poke->tailcall_target,
BPF_MOD_JUMP,
from, to);
if (ret)
pr_err("[X] bpf_arch_text_poke failed: %d\n", ret);
}
}
return 0;
}
static int
__bpf_poke_tailcall(struct bpf_map *map, bool is_hack)
{
struct bpf_array *array = container_of(map, struct bpf_array, map);
struct bpf_array_aux *aux = array->aux;
int ret;
mutex_lock(&aux->poke_mutex);
ret = __bpf_poke_progs(array, is_hack);
mutex_unlock(&aux->poke_mutex);
return ret;
}
|
使用 poke 时,将 bpf prog 上 jmp 的地址改为 trampoline 的地址;而在退出时,将 bpf prog 上 jmp 的地址还原为 tailcall bpf prog 的地址。
实现细节 4:设计用来 trace 的 bpf prog
已知 tailcall bpf prog 的上下文是 kprobe,所以,需要构造一个能够接收 struct pt_regs *ctx 和 u32 index 这两个参数的 bpf prog。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
static __noinline void
__fn(struct pt_regs *regs, u32 index)
{
// This is the actual function that will be called by kernel module.
bpf_printk("tcpconn, __fn, regs: %p, index: %u\n", regs, index);
__u32 key = 0;
struct sock **skp = bpf_map_lookup_elem(&socks, &key);
if (!skp)
return;
struct sock *sk = *skp;
__handle_new_connection(regs, sk, PROBE_TYPE_FENTRY, index);
}
SEC("kprobe/tailcall")
int fentry_tailcall(struct pt_regs *regs)
{
bpf_printk("tcpconn, fentry_tailcall, regs: %p\n", regs);
__fn(regs, 2);
/* This is to avoid clang optimization.
* Or, the index in __fn() will be optimized to 2.
*/
__fn(regs, 3);
return 0;
}
|
这便是 bpf2bpf 的用武之地了:使用 bpf2bpf 构造一个内核模块能够调用的、又满足需求的 bpf prog。
此时,内核模块使用的 trace bpf prog 是 __fn() 而不是 fentry_tailcall()。
但是,fentry_tailcall() 里为什么要调用 2 次 __fn() 呢?
因为,如果只有 1 次调用,那么 __fn() 里的 index 就会被优化成常量 2;导致内核模块传递过来的 index 被忽略掉了。
实现细节 5:使用 Go 将它们串起来
因为内核模块里需要的是 PROG_ARRAY bpf map 的 ID,和 fentry_tailcall() bpf prog 的 ID,所以需要在 Go 里获取它们,并通过内核模块参数的方式传递给内核模块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
mapInfo, err := obj.Progs.Info()
mapID, ok := mapInfo.ID()
progInfo, err := ffObj.FentryTailcall.Info()
progID, ok := progInfo.ID()
if out, err := exec.Command("insmod",
"./kernel/bpf-tailcall-trace.ko",
fmt.Sprintf("bpf_prog_id=%d", progID),
fmt.Sprintf("bpf_map_id=%d", mapID),
).CombinedOutput(); err != nil {
log.Printf("Failed to load bpf-tailcall-trace.ko: %v\n%s", err, out)
return
}
defer func() {
if out, err := exec.Command("rmmod", "bpf-tailcall-trace").CombinedOutput(); err != nil {
log.Printf("Failed to unload bpf-tailcall-trace.ko: %v\n%s", err, out)
}
}()
|
而在 insmod 之前,需要填充好 PROG_ARRAY bpf map。
更多代码细节,请查看源代码:GitHub - Asphaltt/bpf-tailcall-tracer。
小结
已然能够对静态 tailcall 进行 trace,怎么才能对动态 tailcall 进行 trace 呢?
使用内核模块这样 hack 的方式,理论上是可以的,只要能够定位到动态 tailcall 所使用的 jmp 指令位置。
不过,花大力气搞这么复杂的内核模块,不如花更大力气去改进内核,让它支持 trace tailcall。

